Каждый процесс выполняет одну программу и изначально получает один поток управления. Иначе говоря, у процесса есть один счетчик команд, который отслеживает следующую исполняемую команду. Linux позволяет процессу создавать дополнительные потоки (после того, как он начинает выполнение).
Процессы создаются в операционной системе Linux с помощью системного вызова fork, он создает точную копию исходного процесса, называемого родительским процессом (parent process). Новый процесс называется дочерним процессом (child process). У родительского и у дочернего процессов есть собственные (приватные) образы памяти. Если родительский процесс впоследствии изменяет какие-либо свои переменные, то эти изменения остаются невидимыми для дочернего процесса (и наоборот).
Открытые файлы используются родительским и дочерним процессами совместно. Это значит, что если какой-либо файл был открыт в родительском процессе до выполнения системного вызова fork, он останется открытым в обоих процессах и в дальнейшем. Изменения, произведенные с этим файлом любым из процессов, будут видны другому. Такое поведение является единственно разумным, так как эти изменения будут видны также любому другому процессу, который тоже откроет этот файл.
Тот факт, что образы памяти, переменные, регистры и все остальное у родительского и дочернего процессов идентичны, приводит к небольшому затруднению: как процессам узнать, какой из них должен исполнять родительский код, а какой — дочерний? Секрет в том, что системный вызов fork возвращает дочернему процессу число 0, а родительскому — отличный от нуля PID (Process IDentifier — идентификатор процесса) дочернего процесса.
Создание процесса в Linux
```
pid = fork( ); /* если fork завершился успешно, pid > 0 в родительском процессе */
if (pid < 0) {
handle_error(); /* fork потерпел неудачу (например, память или какая-либо таблица переполнена) */
} else if (pid > 0) {
/* здесь располагается родительский код */
} else {
/* здесь располагается дочерний код */
}
```
Если дочерний процесс желает узнать свой PID, то он может воспользоваться системным вызовом getpid. Идентификаторы процессов используются различным образом. Например, когда дочерний процесс завершается, его родитель получает PID только что завершившегося дочернего процесса. Это может быть важно, так как у родительского процесса может быть много дочерних процессов. Поскольку у дочерних процессов также могут быть дочерние процессы, то исходный процесс может создать целое дерево детей, внуков, правнуков и более дальних потомков.
В Linux процессы могут общаться друг с другом с помощью некой формы передачи сообщений. Можно создать канал между двумя процессами, в который один процесс сможет писать поток байтов, а другой процесс сможет его читать. Эти каналы иногда называют трубами (pipes). Синхронизация процессов достигается путем блокирования процесса при попытке прочитать данные из пустого канала. Когда данные появляются в канале, процесс разблокируется.
При помощи каналов организуются конвейеры оболочки. Когда оболочка видит строку вроде
```
sort <f | head
```
она создает два процесса, sort и head, а также устанавливает между ними канал таким образом, что стандартный поток вывода программы sort соединяется со стандартным потоком ввода программы head. При этом все данные, которые пишет sort, попадают напрямую к head, для чего не требуется временного файла. Если канал переполняется, то система приостанавливает работу sort до тех пор, пока head не удалит из него хоть сколько-нибудь данных.
Процессы могут общаться и другим способом — при помощи программных прерываний. Один процесс может послать другому так называемый сигнал (signal). Процессы могут сообщить системе, какие действия следует предпринимать, когда придет входящий сигнал. Варианты такие: проигнорировать сигнал, перехватить его, позволить сигналу убить процесс (действие по умолчанию для большинства сигналов). Если процесс выбрал перехват посылаемых ему сигналов, он должен указать процедуру обработки сигналов. Когда сигнал прибывает, управление сразу же передается обработчику. Когда процедура обработки сигнала завершает свою работу, управление снова передается в то место, в котором оно находилось, когда пришел сигнал (это аналогично обработке аппаратных прерываний ввода-вывода). Процесс может посылать сигналы только членам своей группы процессов (process group), состоящей из его прямого родителя (и других предков), братьев и сестер, а также детей (и прочих потомков). Процесс может также послать сигнал сразу всей своей группе за один системный вызов.
### Системные вызовы управления процессами в Linux
fork. Этот системный вызов (поддерживаемый также в традиционных системах UNIX) представляет собой основной способ создания новых процессов в системах Linux
Он создает точную копию оригинального процесса, включая все описатели файлов, регистры и пр. После выполнения системного вызова fork исходный процесс и его копия (родительский и дочерний процессы) идут каждый своим путем. Сразу после выполнения системного вызова fork значения всех соответствующих переменных в обоих процессах одинаковы, но после копирования всего адресного пространства родителя (для создания потомка) последующие изменения в одном процессе не влияют на другой процесс. Системный вызов fork возвращает значение, равное нулю, для дочернего процесса и значение, равное идентификатору (PID) дочернего процесса, — для родительского. По этому идентифи- катору оба процесса могут определить, кто из них родитель, а кто — потомок.
В большинстве случаев после системного вызова fork дочернему процессу требуется выполнить отличающийся от родительского процесса код. Рассмотрим работу оболочки. Она считывает команду с терминала, с помощью системного вызова fork создает дочерний процесс, ждет выполнения введенной команды дочерним процессом, после чего считывает следующую команду (после завершения дочернего процесса). Для ожидания завершения дочернего процесса родительский процесс делает системный вызов waitpid, который ждет завершения потомка (любого потомка, если их несколько). У этого системного вызова три параметра. Первый параметр позволяет вызывающей стороне ждать конкретного потомка. Если этот параметр равен –1, то в этом случае системный вызов ожидает завершения любого дочернего процесса. Второй параметр представляет собой адрес переменной, в которую записывается статус завершения дочернего процесса (нормальное или ненормальное завершение, а также возвращаемое на выходе значение). Это позволяет родителю знать о судьбе своего ребенка. Третий параметр определяет, будет ли вызывающая сторона блокирована или сразу получит управление обратно (если ни один потомок не завершен).
Если процесс уже завершился, а родительский процесс не ожидает этого события, то дочерний процесс переводится в так называемое состояние зомби (zombie state) — живого мертвеца, то есть приостанавливается. Когда родительский процесс, наконец, обращается к библиотечной процедуре waitpid, дочерний процесс завершается.
### Реализация процессов и потоков в Linux
У каждого процесса есть пользовательская часть, в которой работает программа пользователя. Однако когда один из потоков делает системный вызов, то происходит эмулированное прерывание с переключением в режим ядра. После этого поток начинает работу в контексте ядра с другой картой памяти и полным доступом ко всем ресурсам машины. Это все тот же самый поток, но теперь обладающий большей властью, а также со своим стеком ядра и счетчиком команд в режиме ядра. Это важно, так как системный вызов может блокироваться на полпути: например, в ожидании завершения дисковой операции. При этом счетчик команд и регистры будут сохранены таким образом, чтобы позднее поток можно было перезапустить в режиме ядра.
Ядро Linux внутренним образом представляет процессы как задачи (tasks) при помощи структуры задач task_struct. В отличие от подходов других операционных систем (которые делают различия между процессом, легковесным процессом и потоком), Linux использует структуру задач для представления любого контекста исполнения. Поэтому процесс с одним потоком представляется одной структурой задач, а многопоточный процесс будет иметь по одной структуре задач для каждого из потоков пользователь- ского уровня. Наконец, само ядро является многопоточным и имеет потоки уровня ядра, которые не связаны ни с какими пользовательскими процессами и выполняют код ядра.
Для каждого процесса в памяти всегда находится его дескриптор типа task_struct. Он содержит важную информацию, необходимую ядру для управления всеми процессами (в том числе параметры планирования, списки дескрипторов открытых файлов и т. д.). Дескриптор процесса (вместе с памятью стека режима ядра для процесса) создается при создании процесса.
Для совместимости с другими системами UNIX процессы в Linux идентифицируются при помощи идентификатора процесса (Process Identifier (PID)). Ядро организует все процессы в двунаправленный список структур задач. В дополнение к доступу к дескрипторам процессов при помощи перемещения по связанным спискам PID можно отобразить на адрес структуры задач и немедленно получить доступ к информации процесса.
Структура задачи содержит множество полей. Некоторые из этих полей содержат указатели на другие структуры данных или сегменты (например, содержащие информацию об открытых файлах). Некоторые из этих сегментов относятся к структуре процесса для пользовательского уровня (которая не представляет никакого интереса, если пользовательский процесс не выполняется). Поэтому они могут быть вытеснены в файл подкачки (чтобы не расходовать память на ненужную информацию). Например, несмотря на то что процессу может быть послан сигнал в то время, когда он вытеснен, он не может читать файл. По этой причине информация о сигналах всегда должна находиться в памяти — даже когда процесса в памяти нет. В то же время информация о дескрипторах файлов может храниться в пользовательской структуре и доставляться только тогда, когда процесс находится в памяти и может выполняться.
Информация в дескрипторе процесса подразделяется на следующие категории:
1. Параметры планирования. Приоритет процесса, израсходованное за последний учитываемый период процессорное время, количество проведенного в режиме ожидания времени. Вся эта информация используется для выбора процесса, который будет выполняться следующим.
2. Образ памяти. Указатели на сегменты: текста, данных и стека или на таблицы страниц. Если сегмент текста используется совместно, то указатель текста указывает на общую таблицу текста. Когда процесса нет в памяти, то здесь также содержится информация о том, как найти части процесса на диске.
3. Сигналы. Маски, указывающие, какие сигналы игнорируются, какие перехватываются, какие временно заблокированы, а какие находятся в процессе доставки.
4. Машинные регистры. Когда происходит эмулированное прерывание в ядро, то машинные регистры (включая регистры с плавающей точкой) сохраняются здесь.
5. Состояние системного вызова. Информация о текущем системном вызове (включая параметры и результаты).
6. Таблица дескрипторов файлов. Когда делается системный вызов, использующий дескриптор файла, то файловый дескриптор используется как индекс в этой таблице для обнаружения соответствующей этому файлу структуры данных (i-node).
7. Учетные данные. Указатель на таблицу, в которой отслеживается использованное процессом пользовательское и системное время процессора. Некоторые системы также хранят здесь предельные значения времени процессора, которое может использовать процесс, максимальный размер его стека, количество блоков страниц, которое он может использовать, и пр.
8. Стек ядра. Фиксированный стек для использования той частью процесса, которая работает в режиме ядра.
9. Разное. Текущее состояние процесса, ожидаемые процессом события (если таковые есть), время до истечения интервала будильника, PID процесса, PID родительского процесса, идентификаторы пользователя и группы.
Когда выполняется системный вызов fork, вызывающий процесс выполняет эмулированное прерывание в ядро и создает структуру задач и несколько других сопутствующих структур данных (таких, как стек режима ядра и структура thread_info). Эта структура выделяется на фиксированном смещении от конца стека процесса и содержит несколько параметров процесса (вместе с адресом дескриптора процесса). Поскольку дескриптор процесса хранится в определенном месте, системе Linux нужно всего несколько эффективных операций, чтобы найти структуру задачи для выполняющегося процесса.
Большая часть содержимого дескриптора процесса заполняется значениями из дескриптора родителя. Затем Linux ищет доступный PID, который в этот момент не используется любыми другими процессами, и обновляет элемент хэш-таблицы PID, чтобы там был указатель на новую структуру задачи. В случае конфликтов в хэш-таблице дескрипторы процессов могут быть сцеплены. Она также настраивает поля в task_struct, чтобы они указывали на соответствующий предыдущий/следующий процесс в массиве задач.
В принципе, теперь следует выделить память для данных потомка и сегментов стека и сделать точные копии сегментов родителя, поскольку семантика системного вызова fork говорит о том, что никакая область памяти не используется совместно родительским и дочерним процессами. Текстовый сегмент может либо копироваться, либо использоваться совместно (поскольку он доступен только для чтения). В этот момент дочерний процесс готов работать.
Однако копирование памяти является дорогим удовольствием, поэтому все современные Linux-системы слегка жульничают. Они выделяют дочернему процессу его собственные таблицы страниц, но эти таблицы указывают на страницы родительского процесса, помеченные как доступные только для чтения. Когда какой-либо процесс (дочерний или родительский) пытается писать в такую страницу, происходит нарушение защиты. Ядро видит это и выделяет процессу, нарушившему защиту, новую копию этой страницы, которую помечает как доступную для чтения и записи. Таким образом, копируются только те страницы, в которые дочерний процесс пишет. Такой механизм называется копированием при записи (copy on write). При этом дополнительно экономится память, так как страницы с программой не копируются.
После того как дочерний процесс начинает работу, его код (в нашем примере это копия оболочки) делает системный вызов exec, задавая имя команды в качестве параметра. При этом ядро находит и проверяет исполняемый файл, копирует в ядро аргументы и строки окружения, а также освобождает старое адресное пространство и его таблицы страниц.
Теперь надо создать и заполнить новое адресное пространство. Если системой поддерживается отображение файлов на адресное пространство памяти (как это делается, например, в Linux и практически во всех остальных системах на основе UNIX), то новые таблицы страниц настраиваются следующим образом: в них указывается, что страниц в памяти нет (кроме, возможно, одной страницы со стеком), а содержимое адресного пространства зарезервировано исполняемым файлом на диске. Когда новый процесс начинает работу, он немедленно вызывает страничную ошибку, в результате которой первая страница кода подгружается из исполняемого файла. Таким образом, ничего не нужно загружать заранее, что позволяет быстро запускать программы, а в память загружать только те страницы, которые действительно нужны программам. (Эта стратегия фактически является подкачкой по требованию в ее самом чистом виде. Наконец, в новый стек копируются аргументы и строки окружения, сигналы сбрасываются, а все регистры устанавливаются в нуль. С этого момента новая команда может начинать исполнение.
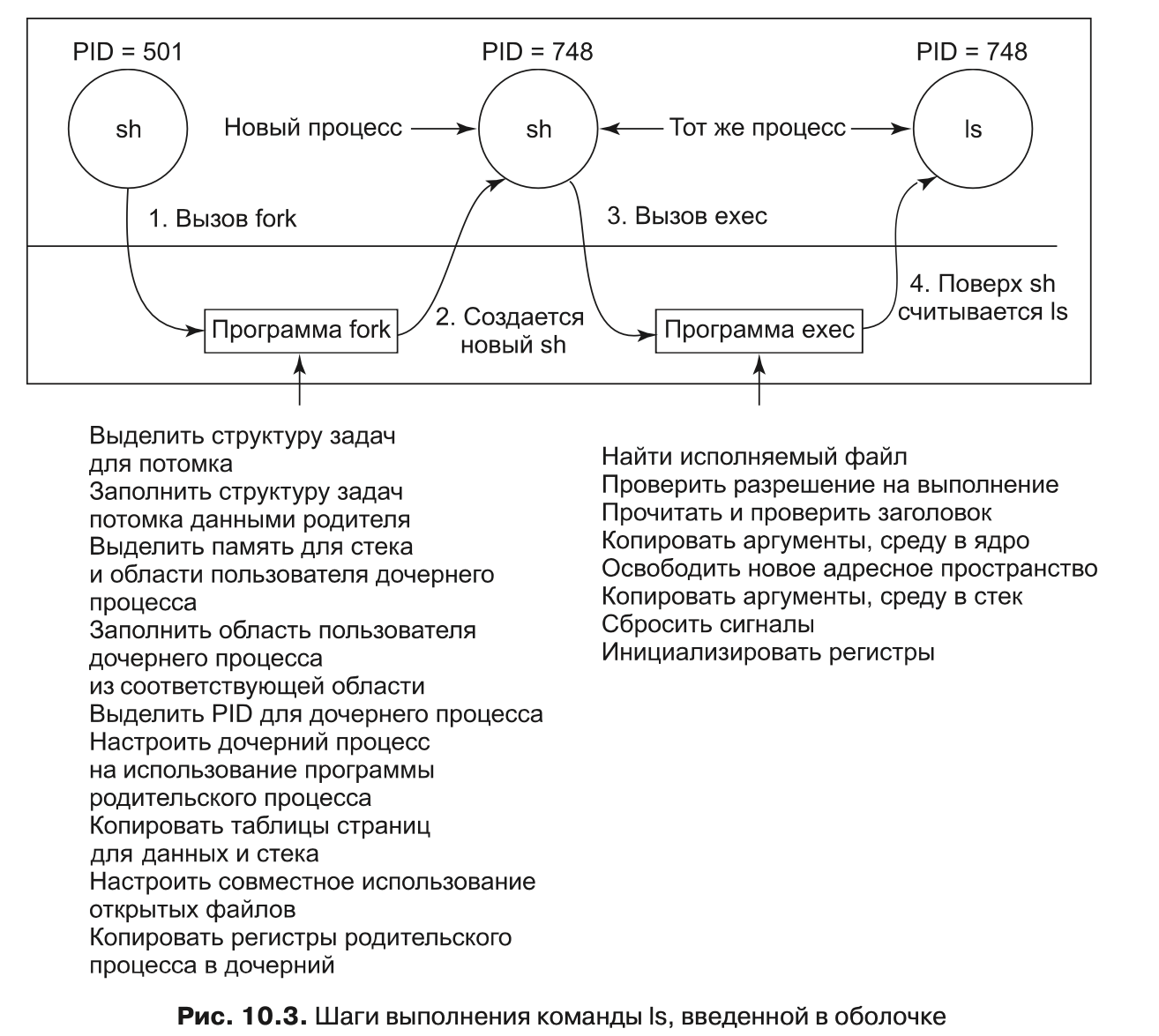
Пользователь вводит с терминала команду ls, оболочка создает новый процесс, клонируя себя с помощью системного вызова fork. Новая оболочка затем делает системный вызов exec, чтобы считать в свою область памяти содержимое исполняемого файла ls. После этого можно приступать к выполнению ls.