Потоки в системе Linux реализованы в ядре, поэтому планирование основано на потоках, а не на процессах.
В операционной системе Linux алгоритмом планирования различаются три класса потоков:
1. Потоки реального времени, обслуживаемые по алгоритму FIFO (First in First Out — первым прибыл, первым обслужен).
2. Потоки реального времени, обслуживаемые в порядке циклической очереди.
3. Потоки разделения времени.
Обслуживаемые по алгоритму FIFO потоки реального времени имеют наивысшие приоритеты и не могут вытесняться другими потоками, за исключением такого же потока реального времени FIFO с более высоким приоритетом, перешедшего в состояние готовности. Обслуживаемые в порядке циклической очереди потоки реального времени представляют собой то же самое, что и потоки реального времени FIFO, но с тем отличием, что они имеют квант времени и могут вытесняться по таймеру. Такой находящийся в состоянии готовности поток выполняется в течение кванта времени, после чего помещается в конец своей очереди. Ни один из этих классов не является на самом деле классом реального времени. Здесь нельзя задать предельный срок выполнения задания и гарантировать его выполнение. Эти классы просто имеют более высокий приоритет, чем потоки стандартного класса разделения времени. Причина, по которой в системе Linux эти классы называются классами реального времени, состоит в том, что операционная система Linux соответствует стандарту P1003.4 (расширения реального времени для UNIX), в котором используются такие имена. Потоки реального времени внутри представлены приоритетами от 0 до 99, причем 0 — самый высокий, а 99 — самый низкий приоритет реального времени.
Обычные потоки составляют отдельный класс и планируются по особому алгоритму, поэтому с потоками реального времени они не конкурируют. Внутри системы этим потокам ставится в соответствие уровень приоритета от 100 до 139, то есть внутри себя Linux различает 140 уровней приоритета (для потоков реального времени и обычных). Так же как и обслуживаемым в порядке циклической очереди потокам реального времени, Linux выделяет обычным потокам время центрального процессора в соответствии с их требованиями и уровнями приоритета. В Linux время измеряется количеством тиков. В старых версиях Linux таймер работал на частоте 1000 Гц и каждый тик составлял 1 мс — этот интервал называют «джиффи» (jiffy — мгновение, миг, момент). В самых последних версиях частота тиков может настраиваться на 500, 250 или даже 1 Гц. Чтобы избежать нерационального расхода циклов центрального процессора на обслуживание прерываний от таймера, ядро может быть даже сконфигурировано в режиме «без тиков», что может пригодиться при запуске в системе только одного процесса или простое центрального процессора и необходимости перехода в энергосберегающий режим. И наконец, на самых новых системах таймеры с высоким разрешением позволяют ядру отслеживать время с джиффи-градацией.
Как и большинство UNIX-систем, Linux связывает с каждым потоком значение nice. По умолчанию оно равно 0, но его можно изменить при помощи системного вызова nice(value), где value меняется от –20 до +19. Это значение определяет статический приоритет каждого потока. Вычисляющий в фоновой программе значение числа π (с точностью до миллиарда знаков) пользователь может использовать этот вызов в своей программе, чтобы быть вежливым по отношению к другим пользователям. Только системный администратор может запросить лучшее по сравнению с другими обслуживание (со значением от –20 до –1). В качестве упражнения вы можете попробовать определить причину этого ограничения.
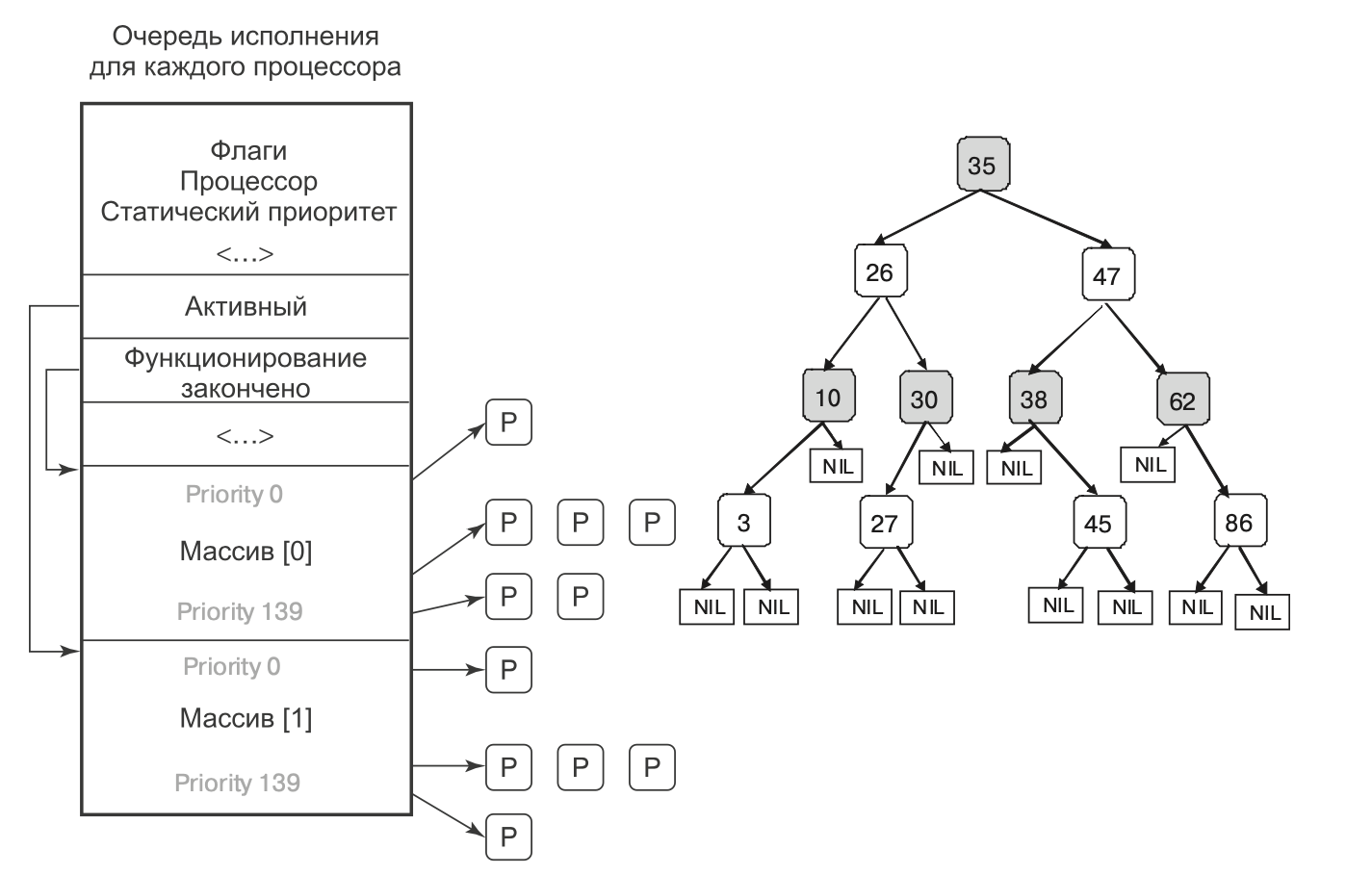
Далее более подробно будут рассмотрены два применяемых в Linux алгоритма планирования. Их свойства тесно связаны с конструкцией очереди выполнения (runqueue), основной структуры данных, используемой планировщиком для отслеживания всех имеющихся в системе задач, готовых к выполнению, и выбора следующей запускаемой задачи. Очередь выполнения связана с каждым имеющимся в системе центральным процессором. Исторически сложилось так, что самым популярным Linux-планировщиком был Linux O(1). Свое название он получил из-за способности выполнять операции управления задачами, такие как выбор задачи или постановка задачи в очередь выполнения за одно и то же время независимо от количества задач в системе. В планировщике O(1) очередь выполнения организована в двух массивах: активных задач и задач, чье время истекло. Как показано на рис. 10.4, а, каждый из них представляет собой массив из 140 заголовков списков, соответствующих разным приоритетам. Каждый заголовок списка указывает на дважды связанный список процессов заданного приоритета Основы работы планировщика можно описать следующим образом.
Планировщик выбирает в массиве активных задач задачу из списка задач с самым высоким приоритетом. Если квант времени этой задачи истек, то она переносится в список задач, чье время истекло (возможно, с другим уровнем приоритета). Если задача блокируется (например, в ожидании события ввода-вывода) до истечения ее кванта времени, то после события она помещается обратно в исходный массив активных задач, а ее квант уменьшается на количество уже использованного времени процессора. После полного истечения кванта времени она также будет помещена в массив задач, чье время истекло. Когда в массиве активных задач ничего не остается, планировщик просто меняет указатели, чтобы массивы задач, чье время истекло, стали массивами активных задач, и наоборот. Этот метод гарантирует, что задачи с низким приоритетом не «умирают от голода» (за исключением случая, когда потоки реального времени со схемой FIFO полностью захватывают ресурсы процессора, что маловероятно).
При этом разным уровням приоритета присваиваются разные размеры квантов времени и больший квант времени присваивается процессам с более высоким приоритетом. Например, задачи с уровнем приоритета 100 получат квант времени 800 мс, а задачи с уровнем приоритета 139 — 5 мс.
Идея данной схемы в том, чтобы быстро убрать процессы из ядра. Если процесс пытается читать дисковый файл, то секунда ожидания между вызовами read невероятно затормозит его. Гораздо лучше позволить ему выполняться сразу же после завершения каждого запроса, чтобы он мог быстро выполнить следующий запрос. Аналогично, если процесс был блокирован в ожидании клавиатурного ввода, то это точно интерактивный процесс, и ему нужно дать высокий приоритет сразу же, как он станет готов к выполнению, чтобы обеспечить хорошее обслуживание интерактивных процессов. Поэтому интенсивно использующие процессор процессы получают все, что остается (когда блокированы все завязанные на ввод-вывод и интерактивные процессы).
Поскольку Linux (как и любая другая операционная система) заранее не знает, будет задача интенсивно использовать процессор или ввод-вывод, она применяет эвристику интерактивности. Для этого Linux различает статический и динамический приоритет. Динамический приоритет потока постоянно пересчитывается для того, чтобы, во-первых, поощрять интерактивные потоки, а во-вторых, наказывать пожирателей процессорных ресурсов. В планировщике O(1) максимальное увеличение приоритета равно –5, поскольку более низкое значение приоритета соответствует более высокому приоритету, полученному планировщиком. Максимальное снижение приоритета равно +5. Планировщик поддерживает связанную с каждой задачей переменную sleep_avg. Когда задача просыпается, эта переменная получает приращение, когда задача вытесняется или истекает ее квант, эта переменная уменьшается на соответствующее значение. Это значение используется для динамического изменения приоритета на величину от –5 до +5. Планировщик Linux пересчитывает новый уровень приоритета при перемещении потока из списка активных в список закончивших функционирование.
Алгоритм планирования O(1) относится к планировщику, ставшему популярным в ранних версиях ядра 2.6, а впервые он был введен в нестабильной версии ядра 2.5. Предыдущие алгоритмы показывали низкую производительность на многопроцессорных системах и не могли хорошо масштабироваться с увеличением количества задач. Поскольку представленное в предыдущем параграфе описание указывает, что решение планирования может быть принято путем доступа к соответствующему списку активных процессов, его можно выполнить за постоянное время О(1), не зависящее от количества процессов в системе. Но несмотря на положительное свойство, заключавшееся в постоянном времени проведения операций, у планировщика O(1) имелись существенные недостатки. Наиболее значимый состоял в том, что эвристическое правило, используемое для определения степени интерактивности задачи, а следовательно уровня ее приоритета, было слишком сложным и несовершенным, что выражалось в низкой производительности интерактивных задач.
Для решения этой проблемы Инго Молнар (Ingo Molnar), который также был создателем планировщика O(1), предложил новый планировщик, названный совершенно справедливым планировщиком (Completely Fair Scheduler (CFS)). Этот планировщик был основан на идее, изначально принадлежавшей Кону Коливасу (Con Kolivas) для более раннего планировщика, и впервые был интегрирован в ядро версии 2.6.23. Он и сейчас является планировщиком по умолчанию для задач, не являющихся задачами реального времени.
Главная идея, положенная в основу CFS, заключается в использовании в качестве структуры очереди выполнения красно-черного дерева. Задачи в дереве выстраиваются на основе времени, которое затрачивается на их выполнение на ценральном процессоре и называется виртуальным временем выполнения — vruntime. CFS подсчитывает время выполнения задачи с точностью до наносекунды. Как показано на рис. 10.4, б, каждый внутренний узел дерева соотносится с задачей. Дочерние узлы слева соотносятся с задачами, которые тратят меньше времени центрального процессора, и поэтому их выполнение будет спланировано раньше, а дочерние записи справа от узла относятся к задачам, которые до этих пор потребляли больше времени центрального процессора. Листья дерева не играют в планировщике никакой роли.
Алгоритм планирования может быть кратко изложен следующим образом. CFS всегда планирует задачу, которой требуется наименьшее количество времени центрального процессора, обычно это самый левый узел дерева. Периодически CFS увеличивает значение vruntime задачи на основе того времени, которое уже было затрачено на ее выполение, и сравнивает его со значением текущего самого левого узла дерева. Если выполняемая задача все еще имеет наименьшее значение vruntime, ее выполнение продолжается. В противном случае она будет вставлена в соответствующее место в красно-черном дереве, и центральный процессор получит задачу, соответсвующую новому самому левому узлу дерева.
Чтобы учесть различия между приоритетами задач и значениями переменной nice, CFS изменяет эффективную ставку, при которой проходит виртуальное время выполнения задания, когда оно запущено на центральном процессоре. Для задач с более низким уровнем приоритета время течет быстрее, их значение vruntime будет расти быстрее,и в зависимости от других задач в системе они будут отлучаться от центрального процессора и заново вставляться в дерево раньше, чем если бы у них был более высокий приоритет. Благодаря этому CFS избегает использования отдельных структур очередей выполнения для разных уровней приоритетов.
Таким образом, выбор узла для выполнения может быть сделан за постоянное время, а вот вставка задачи в очередь выполнения осуществляется за время O(log(N)), где N — количество задач в системе. С учетом уровней загруженности текущих систем это время продолжает оставаться вполне приемлемым, но с увеличением вычисляемого объема узлов и количества задач, которые могут выполняться в системах, в частности в серверном пространстве, вполне возможно, что в дальнейшем будут предложены новые алгоритмы планирования.
Кроме основных алгоритмов планирования Linux-планировщик имеет специальные функциональные возможности, которые особенно полезны для многопроцессорных или многоядерных платформ. Во-первых, с каждым процессором многопроцессорной системы связана структура очереди выполнения. Планировщик старается использовать преимущества родственного планирования и планировать задачи на тот процессор, на котором они выполнялись ранее. Во-вторых, имеется набор системных вызовов для указания требований к родственной принадлежности потока. И наконец, планировщик выполняет периодическую балансировку нагрузки между очередями выполнения разных процессоров, чтобы обеспечить балансировку загрузки системы (выдерживая в то же время определенные требования к производительности и соблюдению родственной принадлежности).
Планировщик рассматривает только готовые к выполнению задачи, которые помещаются в соответствующие очереди выполнения. Те задачи, которые не готовы к выполнению и ждут выполнения различных операций ввода-вывода (или других событий ядра), помещаются в другую структуру данных (очередь ожидания —waitqueue). Такая очередь связана с каждым событием, которого могут дожидаться задачи. Заголовок очереди ожидания содержит указатель на связанный список задач и спин-блокировку. Спин-блокировка нужна для обеспечения одновременного манипулирования очередью ожидания из кода ядра и обработчиков прерываний (или других асинхронных вызовов).