У каждого процесса в системе Linux есть адресное пространство, состоящее из трех логических сегментов: текста, данных и стека. Пример адресного пространства процесса изображен на рис. 10.6 (процесс А). Текстовый сегмент (text segment) содержит машинные команды, образующие исполняемый код программы. Он создается компилятором и ассемблером при трансляции программы (написанной на языке высокого уровня, например C или C++) в машинный код. Как правило, текстовый сегмент доступен только для чтения. Самомодифицирующиеся программы вышли из моды примерно в 1950 году, так как их было слишком сложно понимать и отлаживать. Таким образом, не изменяются ни размеры, ни содержание текстового сегмента.
Сегмент данных (data segment) содержит переменные, строки, массивы и другие данные программы. Он состоит из двух частей: инициализированных и неинициализированных данных. По историческим причинам вторая часть называется BSS (Block Started by Symbol). Инициализированная часть сегмента данных содержит переменные и константы компилятора, значения которых должны быть заданы при запуске программы. Все переменные в BSS должны быть инициализированы в нуль после загрузки.
Например, на языке C можно объявить символьную строку и в то же время проинициализировать ее. Если программа запускается, она предполагает, что эта строка уже имеет свое начальное значение. Чтобы реализовать это, компилятор назначает строке определенное место в адресном пространстве и гарантирует, что в момент запуска программы по этому адресу будет располагаться необходимая строка. С точки зрения операционной системы инициализированные данные не отличаются от текста программы — и тот и другой сегменты содержат сформированные компилятором последовательности битов, которые должны быть загружены в память при запуске программы.
Неинициализированные данные необходимы лишь с точки зрения оптимизации. Если глобальная переменная не инициализирована явным образом, то, согласно семантике языка C, ее начальное значение устанавливается равным 0. На практике большинство глобальных переменных не инициализируются, таким образом, их начальное значение
равно 0. Это можно реализовать следующим образом: создать область исполняемого двоичного файла, точно равную по размеру числу байтов данных, и проинициализировать всю эту область нулями.
Однако (из экономии места в исполняемых файлах) так не делается. Вместо этого файл содержит все явно инициализированные переменные прямо за текстом программы. Все неинициализированные переменные собираются вместе после инициализированных, так что компилятору нужно только записать в заголовок слово, содержащее количество подлежащих выделению байтов.
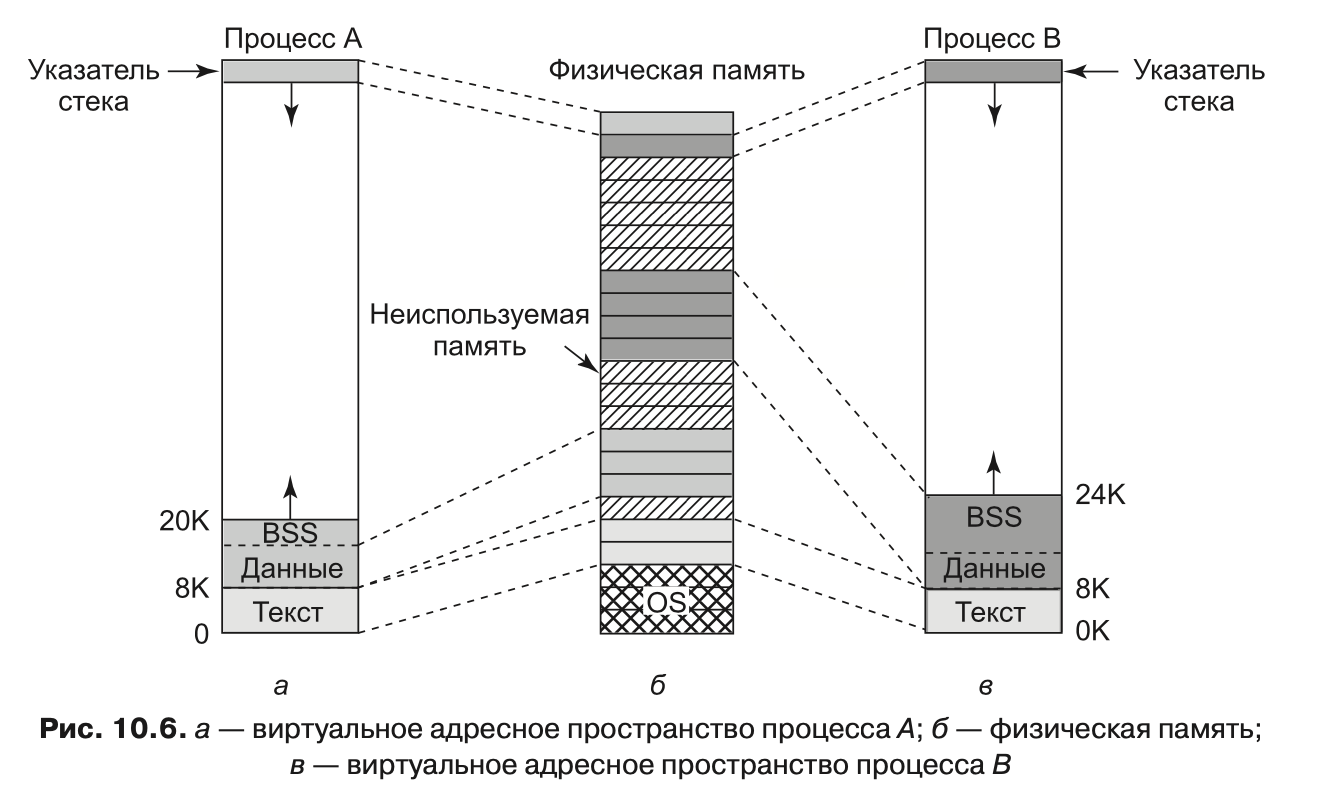
Рассмотрим это еще раз на нашем примере (см. рис. 10.6, а). Здесь текст программы занимает 8 Кбайт, инициализированные данные — также 8 Кбайт. Размер неинициализированных данных (BSS) равен 4 Кбайт. Исполняемый файл содержит только 16 Кбайт (текст + инициализированные данные) плюс короткий заголовок, в котором операционной системе дается указание выделить программе дополнительно 4 Кбайт (после инициализированных данных) и обнулить их перед выполнением программы. Этот трюк позволяет сэкономить 4 Кбайт нулей в исполняемом файле.
Для того чтобы избежать выделения полной нулей физической страницы, во время инициализации Linux выделяет статическую нулевую страницу (защищенную от записи страницу, заполненную нулями). Когда процесс загружается, указатель на область его неинициализированных данных устанавливается на эту нулевую страницу. Когда процесс пытается писать в эту область, то вмешивается механизм копирования при записи и процессу выделяется настоящая страница.
В отличие от текстового сегмента, который не может изменяться, сегмент данных изменяться может. Программы все время модифицируют свои переменные. Более того, многим программам требуется динамическое выделение памяти во время выполнения. Для этого операционная система Linux разрешает сегменту данных расти при выделении памяти и уменьшаться при освобождении памяти. Программа может установить размер своего сегмента данных при помощи системного вызова brk. Таким образом, чтобы выделить больше памяти, программа может увеличить размер своего сегмента данных. Этим системным вызовом активно пользуется библиотечная процедура malloc языка С, используемая для выделения памяти. Дескриптор адресного пространства процесса содержит информацию о диапазоне динамически выделенных областей памяти процесса (который обычно называется кучей — heap).
Третий сегмент — это сегмент стека (stack segment). На большинстве компьютеров он начинается около старших адресов виртуального адресного пространства и растет вниз к 0. Например, на 32-битной платформе х86 стек начинается с адреса 0xC0000000, который соответствует предельному виртуальному адресу, видимому процессам пользовательского режима. Если указатель стека оказывается ниже нижней границы сегмента стека, то происходит аппаратное прерывание, при котором операционная система понижает границу сегмента стека на одну страницу. Программы не управляют явно размером сегмента стека.
Когда программа запускается, ее стек не пуст. Напротив, он содержит все переменные окружения (оболочки), а также командную строку, введенную в оболочке для вызова этой программы. Таким образом, программа может узнать параметры, с которыми она была запущена. Например, когда вводится команда
cp src dest
то запускается программа cp со строкой «cp src dest» в стеке, что позволяет ей определить имена файлов, с которыми ей предстоит работать. Строка представляется в виде массива указателей на символы строки, что облегчает ее разбор.
Когда два пользователя запускают одну и ту же программу (например, текстовый редактор), то в памяти можно было бы хранить две копии программы редактора. Однако такой подход неэффективен. Вместо этого большинством систем Linux поддерживаются текстовые сегменты совместного использования (shared text segemts). На рис. 10.6, а и в мы видим два процесса, A и B, совместно использующие общий тек-стовый сегмент. На рис. 10.6, б мы видим возможную компоновку физической памяти, где оба процесса совместно используют один и тот же фрагмент текста. Отображение выполняется аппаратным обеспечением виртуальной памяти.
Сегменты данных и стека никогда не бывают общими, кроме как после выполнения системного вызова fork, и то только те страницы, которые не модифицируются. Если размер одного из сегментов должен быть увеличен, то отсутствие свободного места в соседних страницах памяти не является проблемой, поскольку соседние виртуальные страницы памяти не обязаны отображаться на соседние физические страницы.
На некоторых компьютерах аппаратное обеспечение поддерживает раздельные адресные пространства для команд и данных. Если такая возможность есть, то система Linux может ее использовать. Например, на компьютере с 32-разрядными адресами (при наличии возможности использования раздельных адресных пространств) можно получить 232 бита адресного пространства для команд и дополнительно 232 бита адресного пространства для сегментов данных и стека. Условная или безусловная передача управления по адресу 0 будет восприниматься как передача управления по адресу 0 в текстовом пространстве, тогда как при обращении к данным по адресу 0 будет использоваться адрес 0 в пространстве данных. Таким образом, эта возможность удваивает доступное адресное пространство.
В дополнение к динамическому выделению памяти процессы в Linux могут обращаться к данным файлов при помощи отображения файлов на адресное пространство памяти (memory-mapped files). Эта функция позволяет отображать файл на часть адресного пространства процесса, чтобы можно было читать из файла и писать в файл так, как если бы это был массив байтов, хранящийся в памяти. Отображение файла на адресное пространство памяти делает произвольный доступ к нему существенно более легким, нежели при использовании таких системных вызовов, как read и write. Совместный доступ к библиотекам предоставляется именно при помощи этого механизма. На рис. 10.7 показан файл, одновременно отображенный на адресные пространства двух процессов по различным виртуальным адресам.
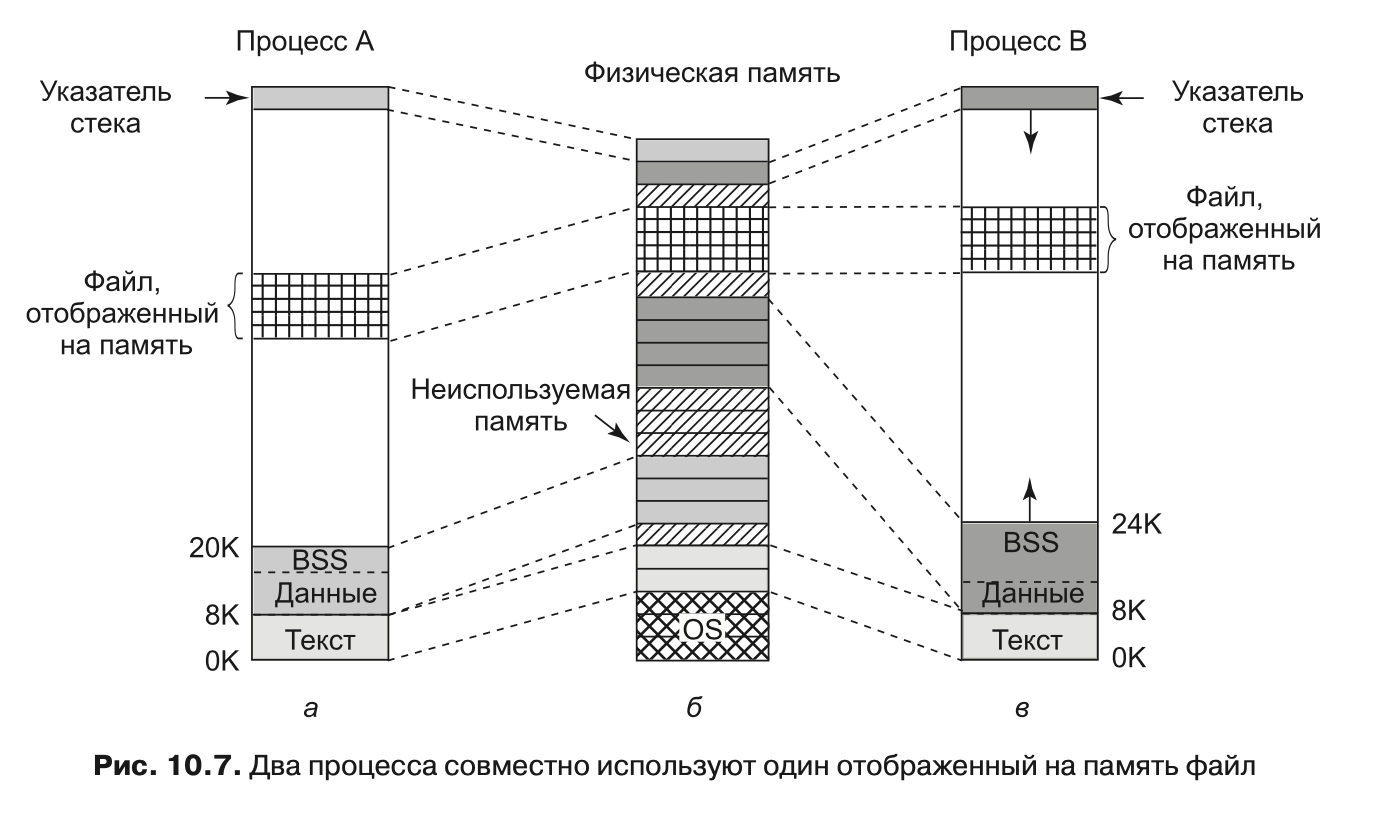
Дополнительное преимущество отображения файла на память заключается в том, что два или более процесса могут одновременно отобразить на свое адресное пространство один и тот же файл. Запись в этот файл одним из процессов мгновенно становится видимой всем остальным. Таким образом, отображение на адресное пространство памяти временного файла (который будет удален после завершения работы процессов) представляет собой механизм реализации общей памяти (с высокой пропускной способностью) для нескольких процессов. В предельном случае два или более процесса могут отобразить на память файл, покрывающий все адресное пространство, получая тем самым такую форму совместного использования памяти, которая является чем-то средним между процессами и потоками. В этом случае (как и у потоков) все адресное пространство используется совместно, но каждый процесс обслуживает, например, свои собственные открытые файлы и сигналы, что отличает этот вариант от потоков. Однако на практике такой способ никогда не применяется.
### Реализация управления памятью в Linux
Каждый процесс системы Linux на 32-разрядной машине обычно получает 3 Гбайт виртуального адресного пространства для себя, а оставшийся 1 Гбайт памяти резервируется для его страничных таблиц и других данных ядра. 1 Гбайт ядра не виден в пользовательском режиме, но становится доступным, когда процесс переключается в режим ядра. Память ядра обычно находится в нижних физических адресах, но отображается в верхний гигабайт виртуального адресного пространства процесса (между адресами 0xC0000000 и 0xFFFFFFFF, это диапазон от 3 до 4 Гбайт). На ныне существующих
64-разрядных машинах семейства x86 для адресации используется не более 48 бит, следовательно, для адресуемой памяти существует теоретический лимит размером 256 Тбайт. Linux разделяет эту память между ядром и пространством пользователя, что дает каждому процессу максимальное виртуальное пространство объемом 128 Тбайт. Адресное пространство создается при инициализации процесса и переписывается с помощью системного вызова exec.
Чтобы несколько процессов могли совместно использовать физическую память, Linux отслеживает использование физической памяти, выделяет при необходимости дополнительную память пользовательским процессам и компонентам ядра, динамически отображает области физической памяти на адресное пространство разных процессов, а также динамически доставляет в память и убирает из нее исполняемые программы, файлы и прочую информацию состояния (по мере необходимости) — чтобы эффективно использовать ресурсы платформы и обеспечить продвижение процесса выполнения. Остальная часть данной главы описывает реализацию различных механизмов ядра Linux, которые отвечают за эти операции.
Управление физической памятью
Вследствие различных аппаратных ограничений, имеющихся на многих системах, не вся их физическая память одинакова, особенно в отношении ввода-вывода и виртуальной памяти. Linux различает три зоны памяти:
1. 2. 3.
ZONE_DMA — это страницы, которые можно использовать для операций DMA. ZONE_NORMAL — это нормальные отображаемые страницы.
ZONE_HIGHMEM — это страницы с адресами в верхней области памяти, которые не имеют постоянного отображения.
Точные границы и компоновка этих зон памяти зависят от архитектуры. На платформах х86 некоторые устройства могут выполнять операции DMA только в первых 16 Мбайт адресного пространства, следовательно, ZONE_DMA находится в диапазоне от 0 до 16 Мбайт. На 64-разрядных машинах имеется дополнительная поддержка для таких устройств, которая может выполнять 32-разрядные операции DMA, и эта область имеет метку ZONE_DMA32. Кроме того, если оборудование наподобие ранних выпусков i386 не может непосредственно отображать адреса памяти выше 896 Мбайт, то все, что выше этой отметки, соответствует ZONE_HIGHMEM. А к ZONE_NORMAL относится все, что между ними. Поэтому на 32-разрядных платформах х86 первые 896 Мбайт адресного пространства Linux отображаются напрямую, а остальные 128 Мбайт адресного пространства ядра используются для доступа к верхним областям памяти. На x86 64 ZONE_HIGHMEM не определена. Ядро поддерживает структуру zone для каждой из этих трех зон и может выполнять выделение памяти для каждой из них по отдельности.
Основная память в Linux состоит из трех частей. Первые две части — ядро и карта памяти — прикреплены в памяти (то есть никогда не вытесняются). Остальная память разделена на страничные блоки, каждый из которых может содержать страницу текста, данных или стека, страницу с таблицей страниц или находиться в списке свободных.
Ядро поддерживает карту памяти, которая содержит всю информацию об использовании физической памяти системы (такую, как зоны, свободные страничные блоки и т. д.). Эта информация (рис. 10.8) организована следующим образом. Прежде всего,Linux поддерживает массив дескрипторов страниц (page descriptors) типа page для каждого физического страничного блока системы (он называется mem_map). Каждый дескриптор страницы содержит: указатель на адресное пространство, к которому принадлежит страница (если она не свободна); пару указателей, которые позволяют ему сформировать дважды связанный список с другими дескрипторами (например, чтобы собрать вместе все свободные страничные блоки), а также несколько прочих полей. На рис. 10.8 дескриптор страницы 150 содержит отображение на то адресное пространство, к которому принадлежит данная страница. Страницы 70, 80 и 200 свободны и связаны вместе. Размер дескриптора страницы равен 32 байтам, поэтому вся mem_map может занимать менее 1 % физической памяти (при размере страничного блока 4 Кбайт).
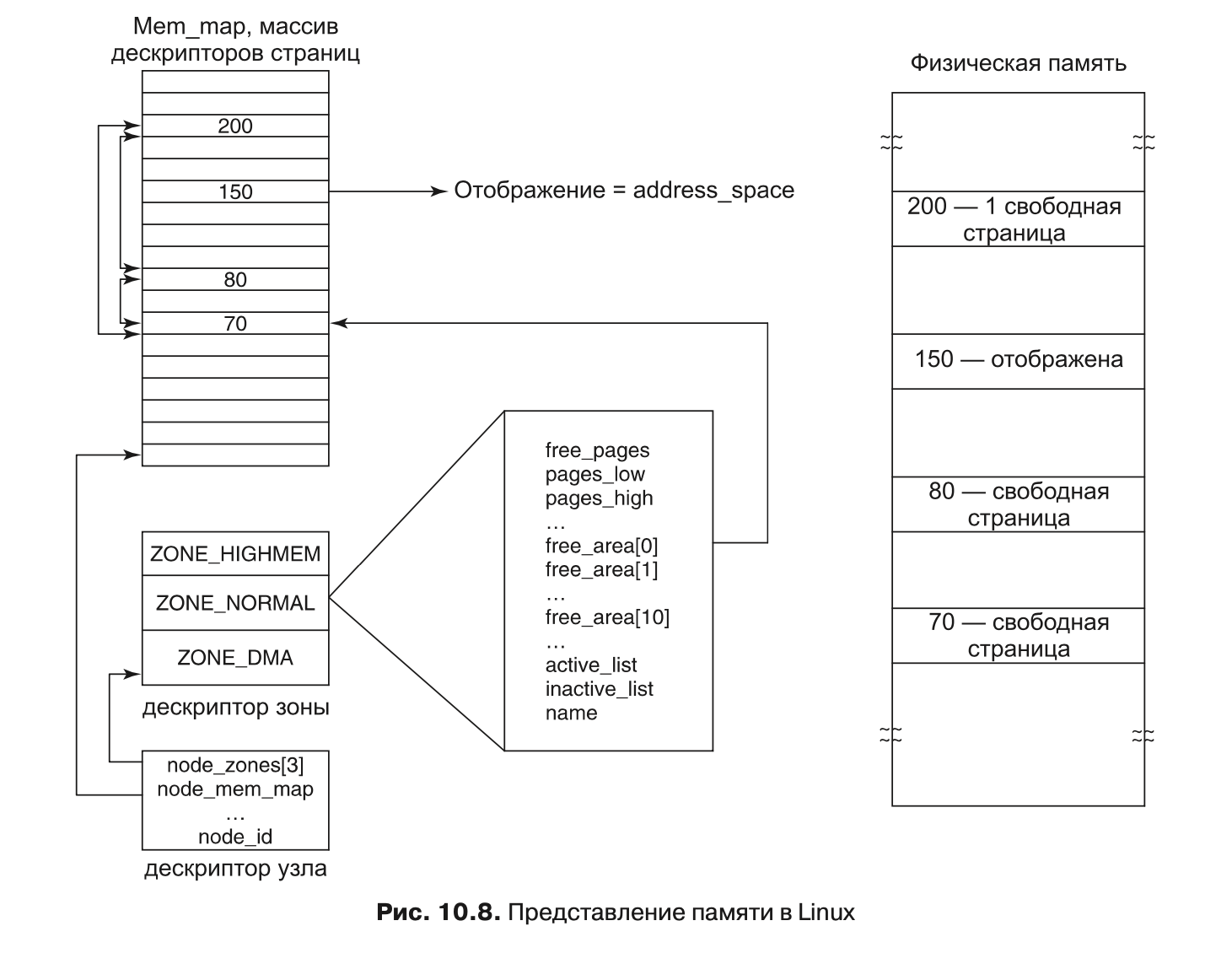
Поскольку физическая память разделена на зоны, для каждой зоны Linux поддерживает дескриптор зоны (zone descriptor). Этот дескриптор содержит информацию об использовании памяти в зоне, такую как количество активных и неактивных страниц, нижний и верхний пределы для алгоритма замещения страниц (который будет описан далее в этой главе), а также много других полей.
Кроме того, дескриптор зоны содержит массив свободных областей. i-й элемент этого массива указывает первый дескриптор страницы первого блока из 2i свободных страниц. Поскольку может существовать много блоков из 2i свободных страниц, то Linux использует в каждом элементе page пару указателей на дескрипторы страниц (чтобы
10.4. Управление памятью в Linux 833
связать их вместе). Эта информация используется в операциях выделения памяти. На рис. 10.8 область free_area[0] (которая идентифицирует все свободные области памяти, состоящие только из одного страничного блока (поскольку 20 = 1)) указывает на страницу 70 — первую из трех свободных областей. Остальные свободные блоки размера 1 можно найти по ссылкам в каждом дескрипторе страниц.
И наконец, поскольку Linux является переносимой на архитектуру NUMA (где разные физические адреса имеют очень сильно различающееся время доступа), для различения физической памяти различных узлов (и во избежание выделения структур данных в чужих узлах) используется дескриптор узла (node descriptor). Каждый дескриптор узла содержит информацию об использовании памяти и зонах данного конкретного узла. На платформах UMA система Linux описывает всю память при помощи одного дескриптора узла. Первые несколько битов каждого дескриптора страниц используются для идентификации узла и зоны, к которой принадлежит данный страничный блок.
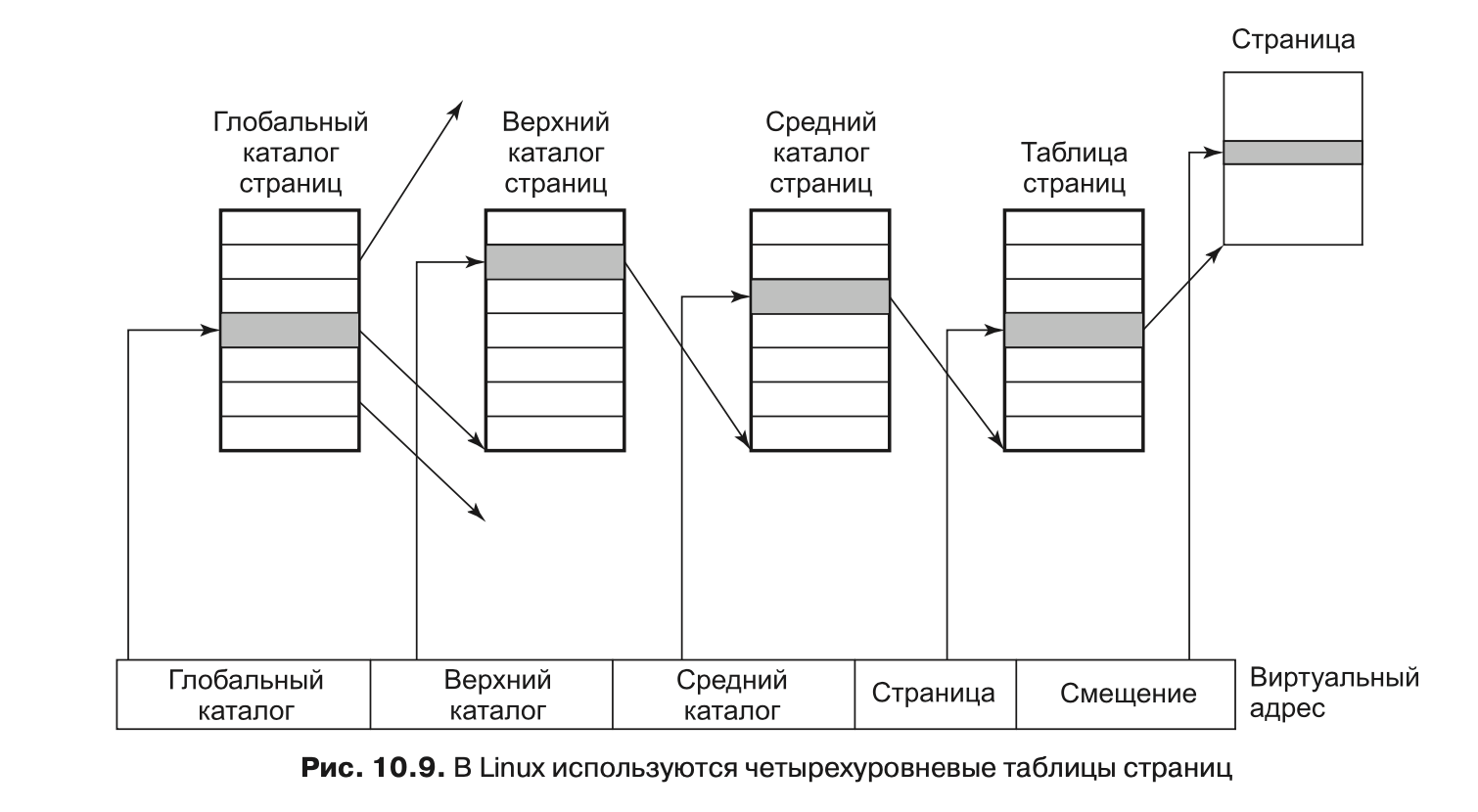
Чтобы механизм подкачки был эффективен на архитектурах х32 и х64, система Linux использует четырехуровневую страничную организацию. Трехуровневая схема была реализована в системе для процессора Alpha, она была расширена после версии Linux 2.6.10, и начиная с версии 2.6.11 используется четырехуровневая схема. Каждый виртуальный адрес разбивается на пять полей, как показано на рис. 10.9. Поля каталогов используются как индекс в соответствующем каталоге страниц (каждый процесс имеет свой приватный каталог). Обнаруженное значение является указателем на один из каталогов следующего уровня, которые тоже проиндексированы полем из виртуального адреса. Выбранный элемент среднего каталога страниц указывает на окончательную таблицу страниц, проиндексированную полем страницы из виртуального адреса. Найденный здесь элемент содержит указатель на нужную страницу. На компьютерах с процессором Pentium используется только двухуровневая организация страниц. В этом случае каждый из верхних и средних каталогов страниц содержит только одну запись. Таким образом, элемент глобального каталога фактически указывает на таблицу страниц. При необходимости может использоваться и трехуровневая страничная организация, для этого размер поля верхнего каталога страниц устанавливается в нуль.
Физическая память используется для различных целей. Само ядро жестко фиксировано — ни одна из его частей никогда не выгружается на диск. Остальная часть памяти доступна для страниц пользователей, страничного кэша и других задач. Страничный кэш содержит страницы с блоками файлов, которые недавно считаны или были считаны заранее (в надежде на то, что они скоро могут понадобиться), либо страницы с блоками файлов, которые надо записать на диск (например, созданные процессами пользовательского режима, которые были выгружены на диск). Его размер динамически меняется, причем он состязается за один и тот же пул страниц с пользовательскими процессами. Страничный кэш в действительности не является настоящим отдельным кэшем, а представляет собой набор страниц пользователя, которые более не нужны и ожидают выгрузки на диск. Если страница, находящаяся в страничном кэше, потребуется снова (прежде, чем она будет удалена из памяти), то ее можно быстро получить обратно.
Кроме того, операционная система Linux поддерживает динамически загружаемые модули, в основном драйверы устройств. Они могут быть произвольного размера, и каждому из них должен быть выделен непрерывный участок в памяти ядра. Для выполнения этих требований система Linux управляет физической памятью таким образом, что она может получить по желанию участок памяти произвольного размера. Для этого используется так называемый дружественный (или «приятельский») алгоритм (buddy algorithm). Он описан далее.
Алгоритм выделения памяти
Linux поддерживает несколько механизмов выделения памяти. Главным механизмом для выделения новых страничных блоков физической памяти является распределитель страниц (page allocator), который работает при помощи широко известного «приятельского» алгоритма.
Основная идея управления блоками памяти заключается в следующем. Изначально память состоит из единого непрерывного участка. В нашем примере на рис. 10.10, а размер этого участка равен 64 страницам. Когда поступает запрос на выделение па мяти, он сначала округляется до степени числа 2, например до 8 страниц. Затем весь блок памяти делится пополам (рис. 10.10, б). Так как получившиеся в результате этого деления участки памяти все еще слишком велики, нижняя половина делится пополам еще (рис. 10.10, в) и еще (рис. 10.10, г). Теперь мы получили участок памяти нужного размера, поэтому он предоставляется вызвавшему процессу (затенен на рис. 10.10, г).
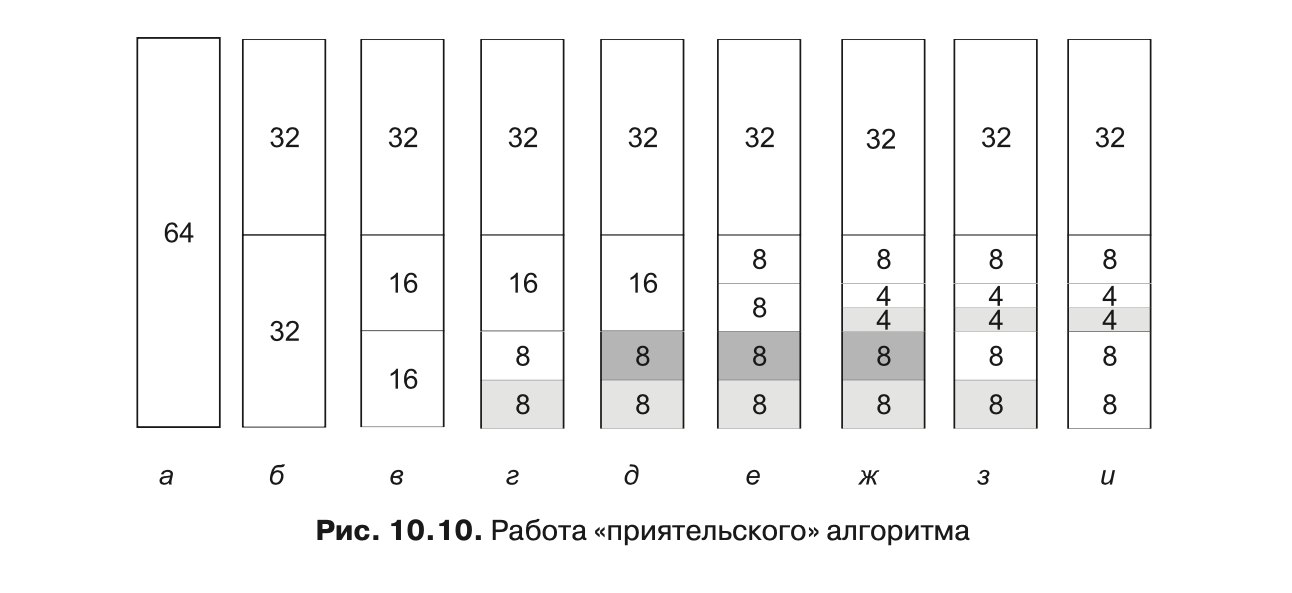
Теперь предположим, что приходит второй запрос на 8 страниц. Он может быть удовлетворен немедленно (рис. 10.10, д). Следом поступает запрос на 4 страницы. Наименьший из имеющихся участков делится надвое (рис. 10.10, е), и выделяется половина (рис. 10.10, ж). Затем освобождается второй 8-страничный участок (рис. 10.10, з). Наконец, освобождается другой 8-страничный участок. Поскольку эти два смежных только что освободившихся участка были «приятелями» (то есть они вышли из одного 16-страничного блока), то они снова объединяются в 16-страничный блок (рис. 10.10, и).
Операционная система Linux управляет памятью при помощи «приятельского» алгоритма. В дополнение к нему имеется массив, в котором первый элемент представляет собой начало списка блоков размером в 1 единицу, второй элемент является началом списка блоков размером в 2 единицы, третий элемент — началом списка блоков размером в 4 единицы и т. д. Таким образом, можно быстро найти любой блок, размер которого кратен степени 2.
Этот алгоритм приводит к существенной внутренней фрагментации, так как если вам нужен 65-страничный участок, то вы должны будете запросить и получите 128-страничный блок.
Чтобы решить эту проблему, в системе Linux есть второй механизм выделения памяти — распределитель фрагментов (slab allocator), выбирающий блоки памяти при помощи «приятельского» алгоритма, а затем нарезающий из этих блоков более мелкие куски и управляющий ими по отдельности.
Поскольку ядро часто создает и уничтожает объекты определенных типов (например, task_struct), то оно зависит от так называемых кэшей объектов (object caches). Эти кэши состоят из указателей на один или несколько кусков, в которых может храниться несколько объектов одного типа. Каждый из этих кусков может быть полным, частично заполненным или пустым.
Например, когда ядру нужно выделить новый дескриптор процесса (то есть новую task_struct), оно ищет в кэше объектов структуры задач и сначала пытается найти частично заполненный кусок и выделить новую task_struct в нем. Если такого куска нет, то оно просматривает список пустых кусков. Наконец (при необходимости) оно выделит новый кусок, поместит в него новую структуру задач и свяжет этот кусок с кэшем объектов структур задач. Служба ядра kmalloc, которая выделяет физически смежные области памяти в адресном пространстве ядра, фактически построена поверх интерфейса кусков и кэша объектов (описанного здесь).
Есть и третий механизм выделения памяти — vmalloc, который используется в тех случаях, когда запрошенная память должна быть смежной только в виртуальном пространстве, а не в физической памяти. На практике это справедливо для большей части запрашиваемой памяти. Одним из исключений являются устройства, которые живут на другой стороне от шины памяти и блока управления памятью (и поэтому не понимают виртуальных адресов). Однако использование vmalloc приводит к некоторому падению производительности, поэтому он применяется в основном для выделения больших количеств непрерывного виртуального адресного пространства (например, для динамической вставки модулей ядра). Все эти механизмы выделения памяти ведут свое происхождение от System V.
### Представление виртуального адресного пространства
Виртуальное адресное пространство делится на однородные, непрерывные и выровненные по границам страниц области. То есть каждая область состоит из участка смежных страниц с одинаковой защитой и страничной организацией. Текстовый сегмент и отображенные файлы являются примерами таких областей (см. рис. 10.8). Между областями виртуального адресного пространства могут быть дыры. Любая ссылка на дыру приводит к фатальной страничной ошибке. Размер страницы фиксирован: например, для Pentium он равен 4 Кбайт, а для Alpha — 8 Кбайт. Начиная с Pentium была добавлена поддержка страничных блоков размером 4 Мбайт. На последних 64-разрядных архитектурах Linux умеет поддерживать большие страницы (huge pages) размером по 2 Мбайт или 1 Гбайт каждая. Кроме того, в режиме расширения физических адресов (Physical Address Extension (PAE)), который используется на некоторых 32-битных архитектурах для увеличения адресного пространства процессов сверх 4 Гбайт, поддерживается также размер страниц 2 Мбайт.
Каждая область описывается в ядре элементом vm_area_struct. Все эти элементы (для одного процесса) связываются вместе в список, отсортированный по виртуальным адресам (чтобы все страницы можно было найти). Когда список становится слишком длинным (более 32 элементов), для ускорения поиска по нему создается дерево. В элементе vm_area_struct перечислены свойства области. Эти свойства включают режим защиты (например, «только для чтения» или «чтение/запись»), информацию о том, закреплен ли он в памяти (не подкачивается) и в каком направлении растет (для сегментов данных — вверх, для стеков — вниз).
В структуре vm_area_struct также записано, является область приватной для процесса или используется совместно с одним или несколькими другими процессами. После выполнения вызова fork система Linux делает копию списка областей для дочернего процесса, но настраивает указатели в родительском и дочернем процессах на одни и те же таблицы страниц. Области помечаются как «чтение/запись», но страницы помечаются как «только для чтения». Если какой-то процесс пытается сделать запись в страницу, то происходит ошибка защиты и ядро видит, что область логически доступна для записи, а страница — нет. Тогда ядро дает процессу копию страницы и помечает ее как «чтение/запись». С помощью этого механизма реализовано копирование при записи.
В структуре vm_area_struct также записано, имеет ли область резервное хранение на диске, и если имеет, то где. Текстовые сегменты используют в качестве резервного хранения исполняемый двоичный файл, а отображаемые на память файлы — дисковый файл. Другие области (такие, как стек) не имеют резервного хранения (до момента вытеснения в файл подкачки).
Дескриптор памяти верхнего уровня mm_struct собирает информацию обо всех областях виртуальной памяти (принадлежащих адресному пространству), о различных сегментах (текста, данных, стека), пользователях (совместно использующих это адресное пространство) и т. д. Ко всем элементам адресного пространства в mm_struct можно обращаться через их дескриптор памяти (двумя способами). Во-первых, они организованы в связанные списки, упорядоченные по адресам виртуальной памяти. Этот способ полезен тогда, когда нужно обращаться ко всем областям виртуальной памяти или когда ядро ищет для выделения область виртуальной памяти определенного размера. Кроме того, элементы структуры vm_area_struct организованы в бинарное дерево (это оптимизированная для быстрого поиска структура). Этот метод используется, когда нужно обратиться к определенной виртуальной памяти. Обеспечивая доступ к элементам адресного пространства процессов этими двумя способами, Linux использует больше памяти на процесс, но позволяет различным операциям ядра использовать тот метод доступа, который более эффективен для текущей задачи.