Принципиальное различие между ними состоит в том, что в виртуальной машине выполняется копия операционной системы целиком, включая ядро, в то время как контейнер использует одно ядро совместно с хост-компьютером. Чтобы понять, что это значит, необходимо сначала разобраться в том, как диспетчер виртуальных машин (Virtual Machine Monitor, VMM) создает их и управляет ими. Начнем с подготовки почвы для этой дискуссии, а именно задумаемся над тем, что происходит при загрузке компьютера.
### Загрузка компьютера
Представьте физический сервер: с несколькими CPU, оперативной памятью и сетевыми интерфейсами. В начале загрузки компьютера запускается специальная программа — BIOS (Basic Input Output System — «базовая система ввода/вывода»). Она проверяет объем доступной оперативной памяти, находит сетевые интерфейсы и все прочие устройства, например мониторы, клавиатуру, подключенные устройства хранения и т. д.
На самом деле значительная часть этой функциональности сегодня перешла в UEFI (Unified Extensible Firmware Interface — универсальный расширяемый интерфейс прошивки), но для простоты будем считать его современным BIOS.
«Переписав» аппаратное обеспечение, система запускает загрузчик, который загружает и запускает код ядра операционной системы — Linux, Windows или какой-либо другой. код ядра работает на более высоком уровне полномочий, чем код приложения. Такой уровень полномочий позволяет ему взаимодействовать с памятью, сетевыми интерфейсами и т. д., в то время как приложения, работающие в пользовательском пространстве, не могут делать этого непосредственно.
В процессорах x86 уровни полномочий организованы в кольца (rings), из которых кольцо 0 имеет наивысшие полномочиями, а кольцо 3 — наименьшие. В большинстве операционных систем в обычных условиях (без виртуальных машин) ядро работает на уровне кольца 0, а код пользовательского пространства — на уровне кольца 3
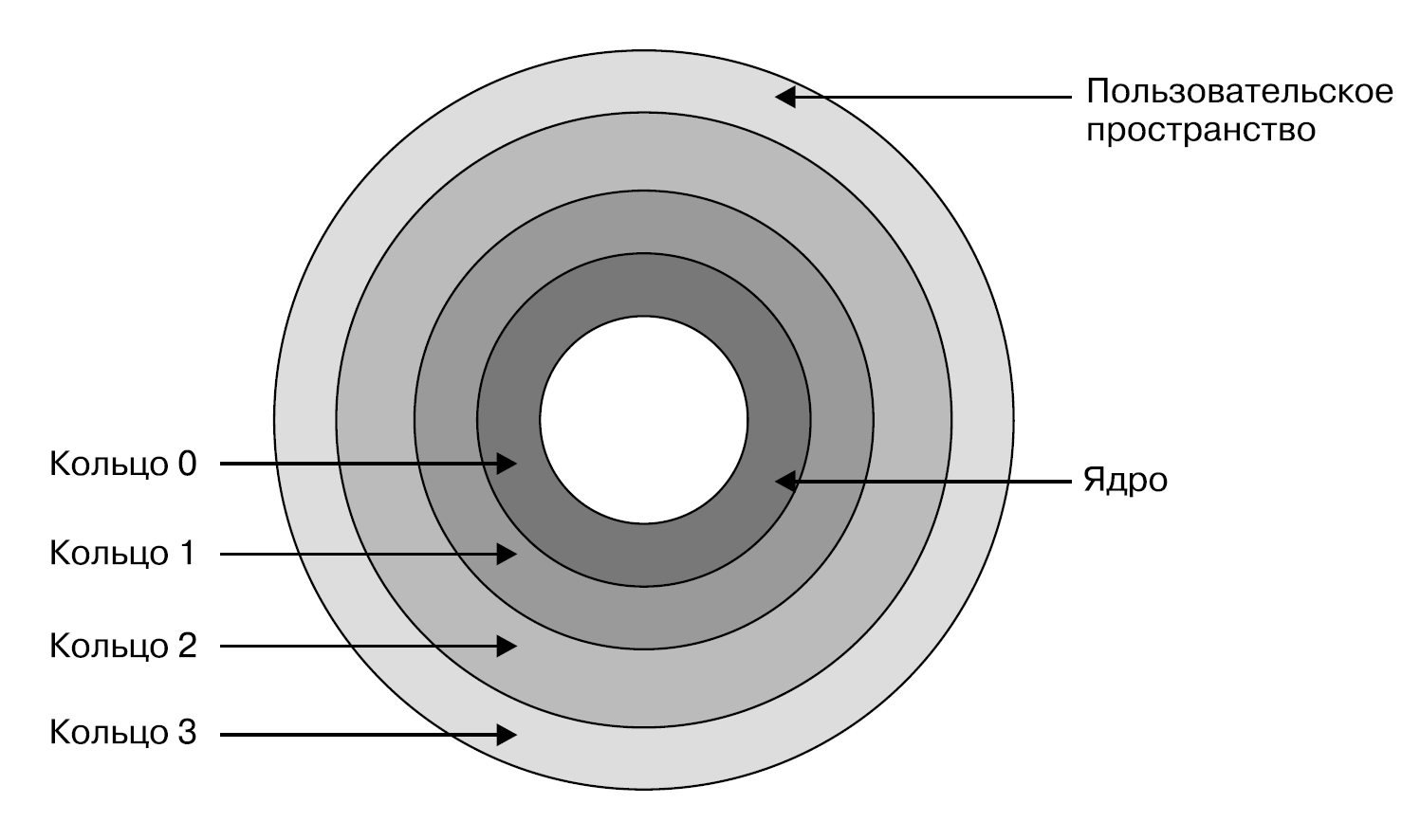
Код ядра (как и любой другой) выполняется на CPU в виде инструкций машинного кода, которые могут включать привилегированные инструкции для обращения к памяти, запуска потоков выполнения CPU и т. д. Подробное изложение всего, что может и будет происходить при инициализации ядра, выходит за рамки данной книги, но фактически цель состоит в монтировании корневой файловой системы, настройке передачи данных по сети и запуске всех системных демонов. Завершив инициализацию, ядро начинает запускать программы в пользовательском пространстве. Оно отвечает за контроль над всем, что необходимо этим программам. Ядро запускает, контролирует и планирует на выполнение потоки выполнения CPU, в которых работают эти программы, и отслеживает эти потоки в собственных структурах данных, соответствующих процессам. Одна из важных сторон функциональности ядра — управление памятью. Ядро выделяет процессам блоки памяти и обеспечивает недоступность блоков памяти одних процессов для других.
### Знакомство с VMM
Как вы только что видели, в обычном случае ядро напрямую управляет ресурсами машины. В мире же виртуальных машин роль первого слоя управления ресурсами играет диспетчер виртуальных машин (Virtual Machine Monitor, VMM), распределяющий ресурсы по виртуальным машинам. У каждой виртуальной машины — свое ядро.
Каждой находящейся под его управлением виртуальной машине VMM выделяет некоторое количество оперативной памяти и ресурсов CPU, настраивает виртуальные сетевые интерфейсы и прочие виртуальные устройства, после чего запускает гостевое ядро с доступом к этим ресурсам.
В обычном сервере BIOS передает ядру подробную информацию о доступных ресурсах компьютера; в случае виртуальной машины VMM делит эти ресурсы и передает гостевым ядрам информацию лишь о той части ресурсов, которые им предоставляются. С точки зрения гостевой ОС ядро считает, что имеет непосредственный доступ к оперативной памяти и устройствам, хотя на самом деле получает доступ лишь к предоставляемой VMM абстракции.
VMM отвечает за то, чтобы гостевая операционная система и ее приложения не нарушали границы выделенных им ресурсов. Например, если такой системе выделен участок памяти на хост-компьютере, то в доступе к памяти вне этого участка будет отказано.
Существует два основных вида VMM, часто называемых (не слишком изобретательно) Type 1 и Type 2. И конечно, между ними есть небольшая «серая зона»!
#### VMM Type 1 (гипервизоры)
В обычных системах ядро операционной системы (например, Linux или Windows) запускает загрузчик. В чистой среде виртуальной машины Type 1 вместо него выполняется специальная программа VMM уровня ядра.
VMM Type 1 известны также под названием гипервизоров (hypervisors). В их числе, например, Hyper-V (https://oreil.ly/FsXVi), Xen (https://xenproject.org/) и ESX/ESXi (https://oreil.ly/ezG3t). Гипервизоры выполняются непосредственно на аппаратном обеспечении («пустой» машине), без какой-либо операционной системы в качестве прослойки.
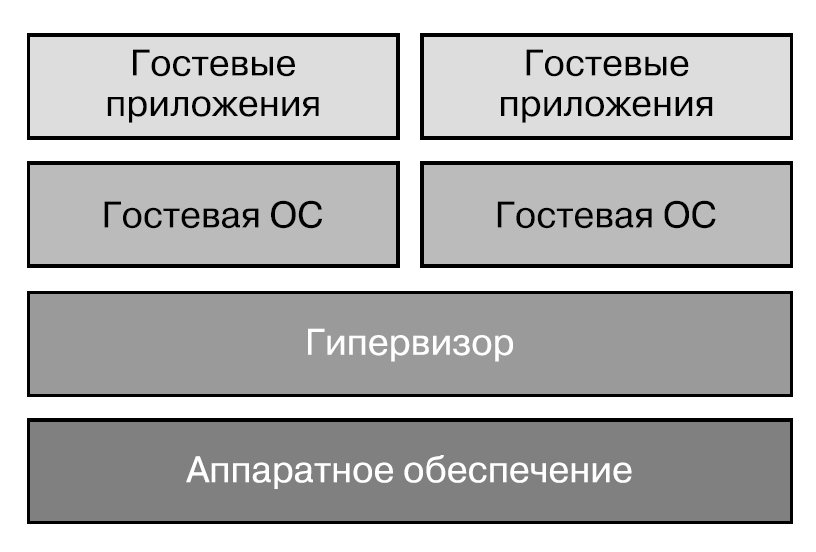
Под «уровнем ядра» я подразумеваю, что гипервизор работает в кольце 0. (Это верно до тех пор, пока мы не начнем рассматривать аппаратную виртуализацию далее в этой главе, но сейчас просто предположим, что в кольце 0.) Ядро гостевой операционной системы работает в кольце 1, как показано на рис. 5.3, поэтому имеет меньше полномочий, чем гипервизор.
#### VMM Type 2
Виртуальные машины, которые вы запускаете на своем ноутбуке или настольном компьютере, например, с помощью чего-то наподобие VirtualBox, относятся к VMM Type 2 (хостируемым VM).
VirtualBox устанавливается как отдельное приложение и управляет затем гостевыми виртуальными машинами, сосуществующими с операционной системой хоста.
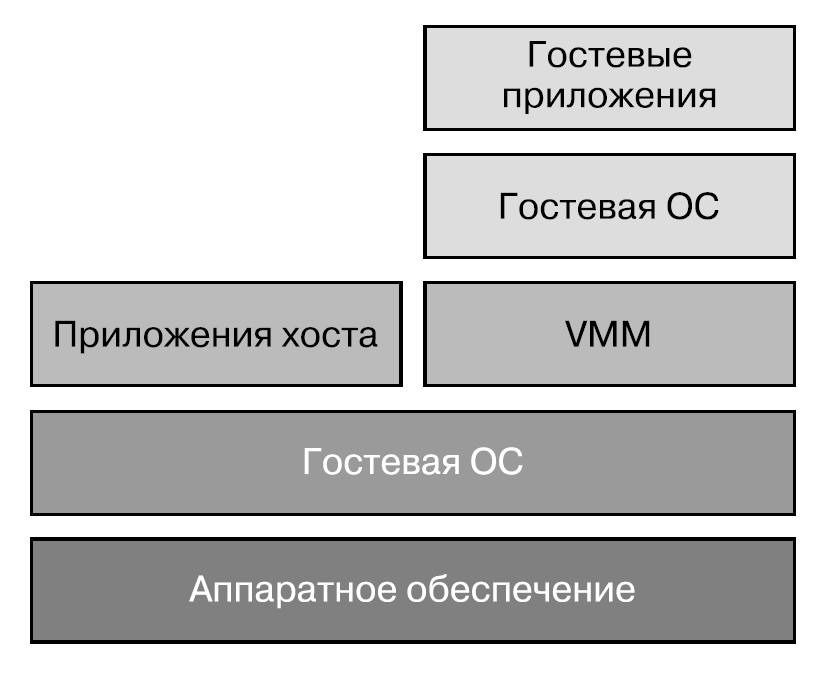
Задумайтесь на минутку, что значит запустить, скажем, Linux внутри macOS. По определению это означает, что должно быть ядро Linux, которое должно отличаться от ядра macOS хоста.
У приложения VMM есть компоненты пользовательского пространства, с которыми вы можете взаимодействовать как пользователь, но оно также устанавливает привилегированные компоненты для виртуализации. В данной главе я расскажу вам более подробно, как это происходит.
Помимо VirtualBox, существуют и другие примеры VMM Type 2, например Parallels (https://parallels.com/) и QEMU (https://oreil.ly/LZmcn).
### Виртуальные машины, работающие в ядре
Я обещала, что границы между VMM Type 1 и Type 2 будут довольно размытыми. В Type 1 гипервизор запускается непосредственно на «пустой» машине; в Type 2 VMM запускается в пользовательском пространстве в операционной системе хоста. Но что, если запустить диспетчер виртуальных машин в ядре операционной системы хоста?
Именно это и происходит в модуле ядра Linux под названием KVM (Kernel-based Virtual Machine), как показано на рис. 5.5.
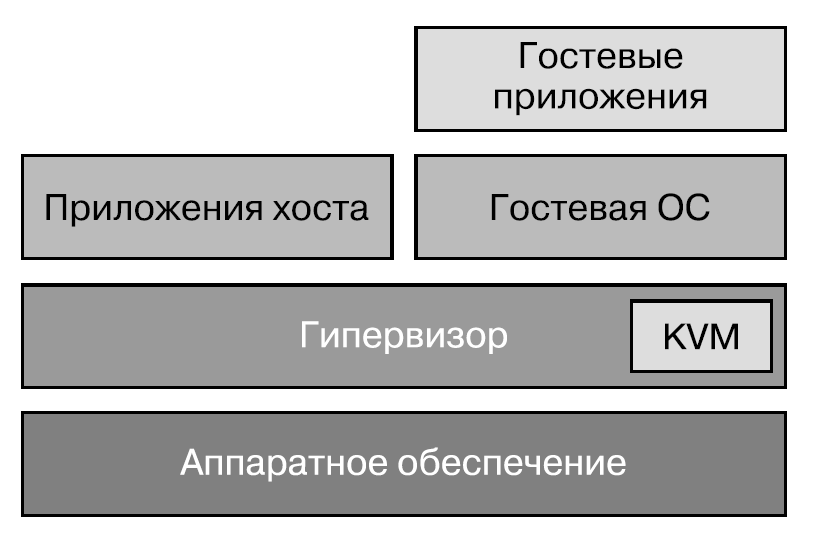
Вообще говоря, KVM считается гипервизором Type 1, поскольку гостевая ОС не должна обращаться к операционной системе хоста, но мне подобная классификация кажется слишком упрощенной.
KVM часто используется совместно с QEMU, которая выше была отнесена к гипервизорам Type 2. QEMU динамически транслирует системные вызовы гостевой ОС в системные вызовы операционной системы хоста. Стоит упомянуть, что QEMU может полноценно задействовать возможности аппаратного ускорения, предоставляемые KVM.
Для виртуализации в VMM используются схожие технологии как в Type 1, так и Type 2 и промежуточных вариантах. Основная их идея называется trap-and-emulate («перехватывай и эмулируй»), хотя, как мы увидим, процессоры x86 требуют некоторой изобретательности при реализации этой идеи.
### «Перехватывай и эмулируй»
Часть инструкций CPU — привилегированные (privileged) в том смысле, что могут выполняться только в кольце 0; попытка выполнения их в прочих кольцах приводит к системному прерыванию (trap). Системное прерывание можно считать своего рода исключением в ПО, которое вызывает срабатывание обработчика ошибок; оно приводит к тому, что процессор вызывает обработчик из кода в кольце 0.
Если VMM работает с полномочиями кольца 0, а код ядра гостевой операционной системы — с более низкими полномочиями, то привилегированная инструкция, выполняемая гостевой ОС, может привести к вызову обработчика из VMM для ее эмуляции. Благодаря этому VMM гарантирует, что гостевые ОС не вмешиваются в работу друг друга через привилегированные инструкции.
К сожалению, привилегированные инструкции — еще не все. Инструкции CPU, способные влиять на ресурсы машины, называются инструкциями, чувствительными к виртуализации (sensitive instructions). VMM приходится обрабатывать эти инструкции вместо гостевой операционной системы, поскольку только VMM действительно видит все ресурсы машины. Существует еще один класс чувствительных к виртуализации инструкций, ведущих себя по-разному при выполнении в кольце 0 или в кольцах с более низкими полномочиями. Обрабатывать эти инструкции приходится опять-таки VMM, поскольку код гостевой операционной системы рассчитан на полномочия кольца 0.
Жизнь разработчиков VMM весьма бы упростилась, если бы все чувствительные к виртуализации инструкции были привилегированными, ведь тогда достаточно было бы просто написать обработчики системных прерываний для всех таких инструкций. К сожалению, не все чувствительные к виртуализации инструкции процессоров x86 еще и привилегированные, поэтому для их обработки диспетчерам виртуальных машин приходится использовать различные методики. Чувствительные к виртуализации, но непривилегированные инструкции считаются невиртуализируемыми.
### Обработка невиртуализируемых инструкций
Существует несколько методик обработки подобных невиртуализируемых инструкций.
* Один вариант — двоичная трансляция (binary translation). VMM выявляет и переписывает в режиме реального времени все непривилегированные, чувствительные к виртуализации инструкции. Это сложная (ресурсоемкая) задача, и современные процессоры x86 поддерживают аппаратную виртуализацию, чтобы упростить двоичную трансляцию.
* Еще один вариант — паравиртуализация (paravirtualization). Вместо динамического изменения инструкций гостевой ОС эта система переписывается так, что не использует набор невиртуализируемых инструкций, фактически выполняя системные вызовы к гипервизору. Эта методика используется, в частности, в гипервизоре Xen.
* Аппаратная виртуализация (например, технология VT-x Intel) позволяет гипервизорам работать на новом уровне, отличающемся дополнительными полномочиями, — известном как режим VMX root, который, по сути, представляет собой кольцо –1. Благодаря этому ядра гостевых операционных систем виртуальной машины могут работать в кольце 0 (то есть в режиме VMX non-root), как если бы они были операционной системой хоста.
### Изоляция процессов и безопасность
Первостепенная задача в сфере безопасности — обеспечение надежной изоляции приложений друг от друга. Если мое приложение может читать выделенную вашему приложению область памяти, значит, у меня есть доступ к вашим данным.
Самый надежный вид изоляции — физическая. Если наши приложения работают на совершенно отдельных компьютерах, то мой код никак не сможет получить доступ к памяти вашего приложения.
Как мы только что говорили, ядро отвечает за управление процессами его пользовательского пространства, включая выделение им памяти. Именно ядро отвечает за то, чтобы одни приложения не могли получить доступ к памяти других. Взломщик может воспользоваться ошибками в механизме управления памятью ядра при их наличии, чтобы получить доступ к памяти, к которой у него доступа быть не должно. И хотя ядро обычно исключительно хорошо проверено в боевых условиях, оно также очень велико и сложно устроено, к тому же постоянно развивается. На момент написания данной книги мне неизвестно о каких-либо серьезных изъянах в изоляции ядра, однако я не могу поручиться за то, что какие-нибудь проблемы не обнаружатся в будущем.
Возникнуть подобные изъяны могут вследствие усложнения нижележащего аппаратного обеспечения. В последние годы производители CPU разработали технологию «упреждающей обработки», при которой процессор «забегает вперед» инструкций, выполняемых в настоящий момент, и предугадывает результаты, чтобы понять, нужно ли на самом деле выполнять ветку кода. Это позволило добиться более высокого быстродействия и вместе с тем открыло дорогу для знаменитых уязвимостей Spectre и Meltdown.
Наверное, вам интересно, почему считается, что гипервизоры изолируют виртуальные машины лучше, чем ядро изолирует свои процессы; в конце концов, гипервизоры тоже управляют памятью и доступом к устройствам и отвечают за разделение виртуальных машин. Совершенно верно, что изъяны в гипервизоре могут привести к серьезным проблемам с изоляцией виртуальных машин. Разница в том, что стоящая перед гипервизорами задача намного, намного проще. В ядре процессы пользовательского пространства частично должны видеть друг друга; очень простой пример: выполните ps — и увидите запущенные на той же машине процессы. Вы можете (при наличии соответствующих прав) получить доступ к информации об этих процессах,заглянув в каталог /proc. Вы можете намеренно использовать память совместно в нескольких процессах через механизм IPC и, собственно, с помощью совместно используемой памяти. Все эти механизмы, с помощью которых один процесс может на законных основаниях получать информацию о другом, ослабляют изоляцию. Так происходит вследствие возможных изъянов, из-за которых подобный доступ может предоставляться в неожиданных или непредусмотренных обстоятельствах.
В случае же виртуальных машин никакого эквивалента этому явлению нет; процессы одной (виртуальной) машины не видны из другой. Управление памятью требует меньшего объема кода, поскольку гипервизору не нужно учитывать ситуации, при которых машинам может потребоваться использовать память совместно — это просто нехарактерно для виртуальных машин. В результате гипервизоры обычно намного меньше и проще устроены, чем полноценные ядра. Ядро Linux включает более 20 миллионов строк кода (https://oreil.ly/FHKhp); а гипервизор Xen — всего 50 тысяч (https://oreil.ly/1MWub).
А где меньше кода и меньше степень сложности — меньше и поверхность атаки, а значит, и вероятность изъянов, которыми мог бы воспользоваться злоумышленник. Поэтому считается, что границы зон безопасности у виртуальных машин прочнее.
Тем не менее эксплойты в виртуальных машинах встречаются. Дархан Тан (Darshan Tank), Акшай Агарвал (Akshai Aggarwal) и Нирбхай Чобей (Nirbhay Chaubey) (https://oreil.ly/HCXBO) описали таксономию различных типов атак, а Национальный институт стандартов и технологий (NIST) опубликовал методические рекомендации по укреплению безопасности (https://oreil.ly/W_b7o) виртуализированных сред.
### Недостатки виртуальных машин
Вероятно, я уже настолько убедила вас в преимуществах изоляции виртуальных машин, что вы недоумеваете: зачем вообще использовать контейнеры? У виртуальных машин, по сравнению с контейнерами, есть несколько недостатков.
* Время загрузки виртуальной машины на несколько порядков больше, чем у контейнера. В конце концов, запуск контейнера означает просто запуск
нового процесса Linux, а не полномасштабную загрузку и инициализацию виртуальной машины. Относительно медленная загрузка виртуальных машин означает медленную масштабируемость, не говоря уже о важности быстрой загрузки в случае частой поставки нового кода, например несколько раз в день. (Впрочем, обсуждаемая в разделе «Виртуальная машина Firecracker» на с. 144 технология виртуализации Firecracker от Amazon обеспечивает виртуальные машины с очень быстрой загрузкой, порядка 100 миллисекунд на момент написания данной книги.)
* Благодаря контейнерам разработчики могут «создать один раз, выполнять где угодно» быстро и эффективно. Можно, конечно, хотя это и займет немало времени, собрать образ виртуальной машины целиком и запускать его на своем ноутбуке, но данный подход не стал чрезмерно популярным среди разработчиков, в отличие от контейнеров.
* В современных облачных средах при аренде виртуальной машины выбирается CPU и объем оперативной памяти, за которые необходимо вносить арендную плату вне зависимости от того, какая часть этих ресурсов фактически используется работающим в ней кодом приложения.
* Каждая виртуальная машина влечет накладные расходы по выполнению всего ядра целиком. Благодаря совместному использованию ядра контейнеры гораздо рациональнее задействуют ресурсы и демонстрируют высокую производительность.
Выбор между виртуальными машинами или контейнерами означает выбор множества компромиссов относительно таких факторов, как быстродействие, цена, удобство, риски и прочность границ зон безопасности между приложениями.
### Изоляция контейнеров по сравнению с изоляцией виртуальных машин
Контейнеры представляют собой просто процессы Linux с ограничениями на доступные ресурсы. Ядро изолирует их с помощью механизмов пространств имен, контрольных групп и изменения корневого каталога, предназначенных специально для изоляции процессов. Однако сам факт совместного использования контейнерами ядра означает, что их изоляция слабее по сравнению с виртуальными машинами.
Для усиления изоляции можно применить дополнительные средства безопасности и различные «песочницы».
Изоляция контейнеров легко нарушается из-за неправильных настроек.