Идея заключается в ограничении входящего/исходящего сетевого трафика контейнера только заданными пунктами назначения.
Например, рассмотрим разбитое на микросервисы приложение для электронной коммерции. Один из его микросервисов, допустим, может отвечать за поиск товаров: получать поисковые запросы от конечных пользователей и производить поиск в базе товаров. Контейнерам, составляющим этот сервис, вовсе не требуется обмениваться информацией, скажем, с платежным шлюзом.
Прежде чем заниматься нюансами того, как реализуется защита контейнеров брандмауэрами, вспомним устройство семиуровневой сетевой модели и проследим путь IP-пакетов по сети.
### Сетевая модель OSI
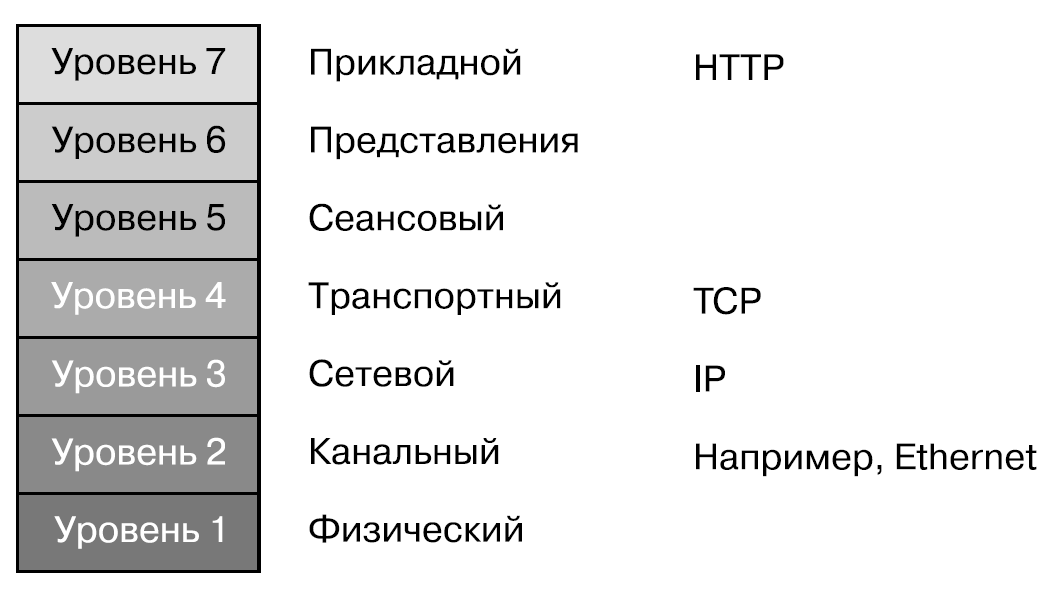
* Уровень 7 — прикладной (уровень приложений). Представьте приложение, которое выполняет веб-запрос или отправляет запрос к воплощающему REST API, — и поймете, что происходит на уровне 7. Такой запрос обычно направляется по URL, и в целях его маршрутизации к месту назначения доменное имя преобразуется в IP-адрес с помощью протокола разрешения доменных имен (Domain Name Resolution), реализуемого сервисом доменных имен (Domain Name Service, DNS).
* Уровень 4 — транспортный, обычно данные передаются по нему в виде TCP или UDP-пакетов. На этом уровне используются номера портов.
* Уровень 3 — уровень, на котором перемещаются IP-пакеты и работают IP-маршрутизаторы. Каждой IP-сети выделяется множество IP-адресов, и когда контейнер присоединяется к ней, ему назначается один из этих IP-адресов. В данной главе нам неважно, используется ли в IP-сети протокол IP v4 или IPv6, — можете считать это несущественным нюансом реализации.
* Уровень 2 — здесь пакеты данных направляются к конечным точкам, соединенным с физическим или виртуальным интерфейсом (которые мы обсудим чуть позже). Существует несколько протоколов уровня 2, включая Ethernet, Wi-Fi и, если мысленно перенестись в прошлое, Token Ring. (Wi-Fi здесь немного все запутывает, поскольку охватывает как уровень 2, так и уровень 1.)
* Уровень 1 называется физическим, хотя учтите, что интерфейсы на этом уровне могут быть виртуальными. У физического компьютера есть физическое сетевое устройство, подключенное к кабелю или беспроводному передатчику.
### Отправка IP-пакета
Представьте приложение, которое хочет отправить сообщение на целевой URL. Поскольку речь идет о приложении, то из предыдущего определения следует, что это происходит на уровне 7.
Первый шаг — поиск по DNS IP-адреса, соответствующего имени хоста в этом URL. DNS может быть задан локально (например, в файле /etc/hosts) или разрешаться путем DNS-запроса к удаленному сервису, расположенному по заданному в настройках IP-адресу. (Если приложению известен IP-адрес, по которому нужно отправить сообщение, а не URL, то шаг разрешения DNS пропускается.)
Когда сетевой стек знает целевой IP-адрес пакета, производится выбор маршрутизации на уровне 3, состоящий из двух частей.
1. От целевого пункта нас может отделять несколько транзитных участков IP-сети. При заданном целевом IP-адресе каков IP-адрес следующего транзитного участка?
2. Какой интерфейс соответствует этому IP-адресу следующего транзитного участка?
Далее пакет преобразуется в кадры Ethernet, а IP-адрес следующего транзитного участка сопоставляется с соответствующим MAC-адресом. Для этого используется протокол разрешения адресов (Address Resolution Protocol, ARP), который сопоставляет IP-адреса с MAC-адресами. Если сетевому стеку пока еще не известен MAC-адрес, который соответствует следующему IP-адресу (он может уже содержаться в кэше ARP), то его можно выяснить, применив ARP.
После того как сетевой стек получит MAC-адрес следующего транзитного участка, сообщение отправляется через интерфейс. В зависимости от реализации сети для этого может использоваться прямое соединение либо интерфейс может подключаться к мосту (bridge).
Чтобы понять, что такое мост, представьте физическое устройство, в которое включены несколько кабелей Ethernet. Вторые концы всех кабелей включены в сетевые карты устройств — например, компьютеров. Каждой физической сетевой карте соответствует уникальный MAC-адрес, зашитый в нее производителем. Мост выясняет MAC-адреса всех устройств, расположенных на вторых концах кабелей, включенных в его интерфейс. Все подключенные к мосту устройства могут отправлять через него друг другу пакеты. При передаче данных по сети между контейнерами мосты реализованы программно, а не аппаратно, а роль кабелей Ethernet играют виртуальные интерфейсы Ethernet. Таким образом, сообщение поступает в мост, который на основе MAC-адреса следующего транзитного участка определяет, в какой интерфейс его направить.
Когда сообщение достигает другого конца Ethernet-соединения, IP-пакет извлекается и переводится обратно на уровень 3. Данные инкапсулируются с заголовками на различных уровнях сетевого стека.
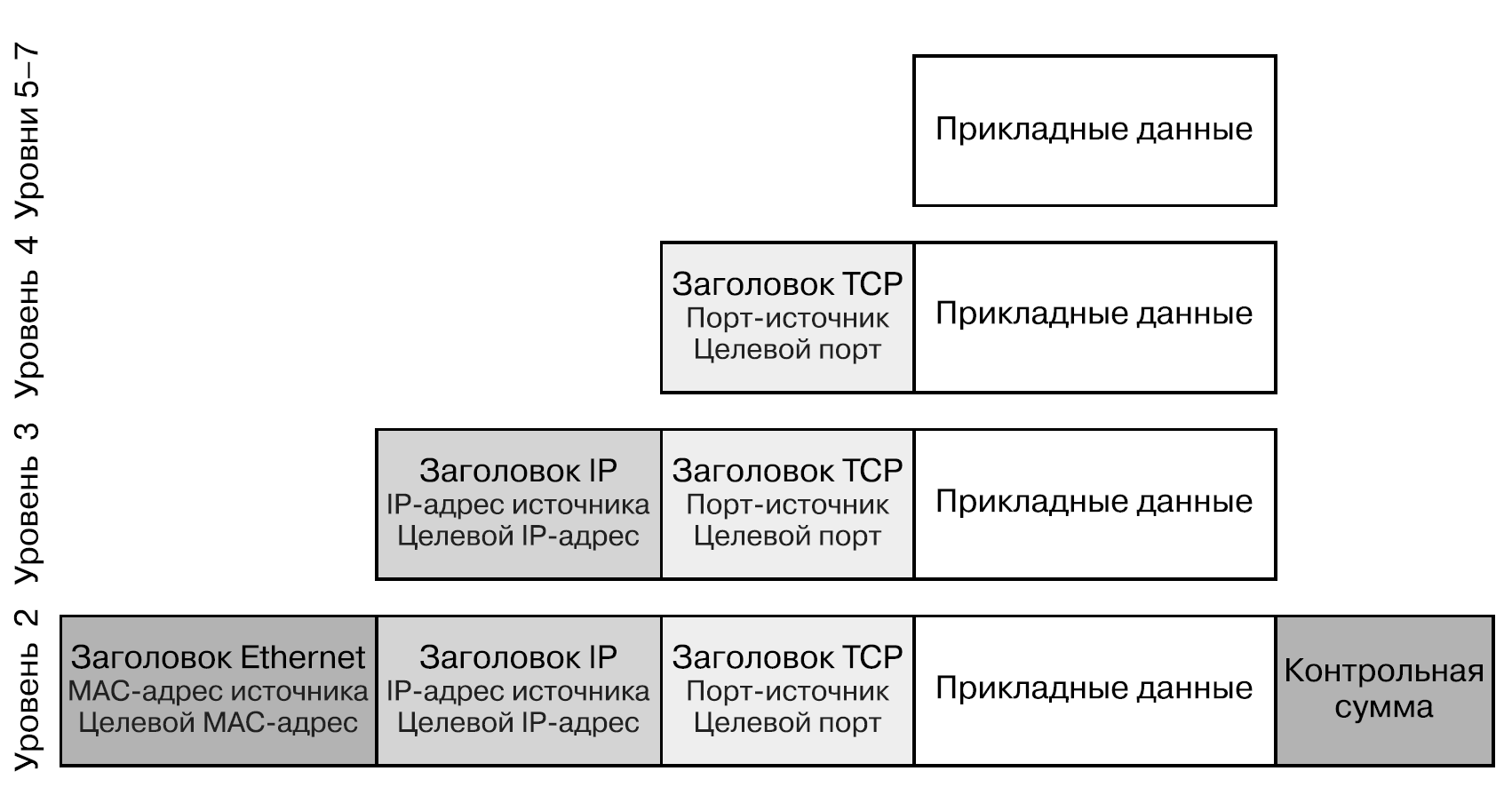
Если это конечный пункт назначения пакета, то данные передаются приложению-получателю. Впрочем, если для пакета это всего лишь очередной транзитный участок, то сетевому стеку приходится снова принимать решение о том, куда отправлять пакет далее.
### IP-адреса контейнеров
IP-адреса контейнеров могут совпадать с IP-адресами их хостов, но для них может применяться и отдельный сетевой стек, оперирующий в их собственном пространстве имен сети.
### Сетевая изоляция
В мире контейнеров Docker значительно упрощает настройку большого количества сетей благодаря команде docker network, но в модель Kubernetes, где любой модуль может (если не учитывать сетевые стратегии и настройки безопасности) обращаться по IP-адресу к любому другому модулю, подобное вписывается плохо.
В Kubernetes же передача данных по сети между контейнерами основывается на сетевых стратегиях (https://oreil.ly/sHh4p), работающих на уровнях 3/4.
### Маршрутизация на уровнях 3/4 и правила
Как вы уже знаете, основная задача маршрутизации на уровне 3 — выбор следующего транзитного участка для IP-пакета. Это решение основывается на наборе правил, которые описывают, какой интерфейс следует использовать для достижения тех или иных адресов. Но это лишь малая часть возможностей правил уровня 3: на нем можно производить много других интересных вещей, например игнорировать пакеты или выполнять различные операции с IP-адресами, скажем, в целях реализации балансировки нагрузки, NAT, брандмауэров и стратегий безопасности сети. Правила также могут применяться на уровне 4, для учета номеров портов. В основе этих правил лежит возможность netfilter (https://netfilter.org/) ядра.
Средство netfilter служит для фильтрации пакетов. В нем используется набор правил, описывающий, что делать с пакетом в зависимости от его адреса-источника и целевого адреса.
### Утилита iptables
Применительно к передаче данных по сети между контейнерами наиболее интересны таблицы — filter и nat.
* таблица filter предназначена для того, чтобы определить, игнорировать пакет или передать его далее;
* таблица nat предназначена для преобразования адресов.
В Kubernetes сетевой прокси kube-proxy использует правила iptables для балансировки объемов трафика, направляемого к сервисам. Сервис — это абстракция, которая сопоставляет название сервиса с набором модулей Kubernetes. С помощью DNS название сервиса разрешается (преобразуется) в IP-адрес. Когда поступает пакет, предназначенный для этого IP-адреса сервиса, находится соответствующее даному целевому адресу правило iptables и он меняется на целевой адрес одного из модулей. Если набор модулей для этого сервиса меняется, то правила iptables перезаписываются соответствующим образом на всех хостах.
посмотреть правила iptables для сервиса. Для примера возьмем кластер Kubernetes, в котором для сервиса nginx используется две реплики:
```
$ kubectl get svc,pods -o wide
```
Основная проблема при работе с iptables заключается в падении производительности при большом количестве сложных правил на каждом хосте. На самом деле то, как kube-proxy использует iptables, — известное узкое место в смысле производительности при работе Kubernetes в крупных системах. 2000 сервисов по десять модулей каждый означает 20 000 дополнительных правил iptables на каждом узле. Чтобы решить эту проблему, в Kubernetes была добавлена возможность использования IPVS для сервисов балансировки нагрузки.
### IPVS
Виртуальный сервер IP (IP Virtual Server, IPVS) иногда называют балансировщиком нагрузки уровня 4 или коммутатором LAN уровня 4. Он представляет собой еще одну реализацию сетевых правил, подобную iptables, оптимизированную для балансировки нагрузки за счет хранения правил пересылки в хеш-таблицах.
Подобная оптимизация значительно повышает производительность в случае использования kube-proxy, но это не повод делать далеко идущие выводы относительно производительности сетевых плагинов, которые реализуют сетевые стратегии.
Неважно, с помощью чего строится работа с правилами netfilter — iptables или IPVS, все равно они функционируют внутри ядра. Оно используется совместно всеми расположенными на хосте контейнерами, поэтому обеспечение соблюдения сетевых стратегий
### Сетевые стратегии
Сетевые стратегии в Kubernetes применяются к входящему/исходящему трафику различных модулей. Стратегии описываются в разрезе портов, IP-адресов, сервисов или маркированных модулей. Если стратегия запрещает отправку/получение конкретного сообщения, то сети приходится либо отказать в установлении соединения, либо игнорировать пакеты, которые соответствуют данному сообщению.
Во многих реализациях сетевых стратегий используются правила netfilter. Посмотрим на правило сетевой стратегии Kubernetes, реализованное в утилите iptables. Ниже представлен простой объект NetworkPolicy, который разрешает модулям доступ к сервису my-nginx только в том случае, когда они помечены access=true:
```
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: access-nginx
spec:
podSelector:
matchLabels:
app: my-nginx
ingress:
- from:
- podSelector:
matchLabels:
access: "true"
```
В результате создания подобной сетевой стратегии в таблице filter возникает дополнительное правило iptables:
```
Chain WEAVE-NPC-INGRESS (1 references)
target prot opt source destination
ACCEPT all -- anywhere anywhere match-set weave-{U;]TI.l|MdRzDhN7$NRn[t)d src match-set weave-vC070kAfB$if8}PFMX{V9Mv2m dst /* pods: namespace: default, selector: access=true -> pods: namespace: default, selector: app=my-nginx (ingress) */
```
Правила iptables для сопоставления с сетевой стратегией создает сетевой плагин Weave, а не один из базовых компонентов Kubernetes.
Правило match-set не предназначено для чтения человеком, но комментарий вполне соответствует нашим ожиданиям относительно того, что это правило разрешает трафик из модулей в пространстве имен по умолчанию с меткой access=true, направляемый к модулям в пространстве имен по умолчанию с меткой app=my-nginx.
### Практические рекомендации для сетевых стратегий
Какие бы утилиты вы ни использовали для создания, управления и обеспечения соблюдения сетевых стратегий, существует несколько рекомендаций.
* Отказ по умолчанию. Следуя принципу минимума полномочий, задавайте стратегии для всех пространств имен, которые бы отклоняли входящий трафик по умолчанию (https://oreil.ly/L6OjC), и лишь затем добавьте стратегии, которые будут позволять прохождение ожидаемого вами трафика.
* Отказ по умолчанию для исходящего трафика. Стратегии исходящего трафика относятся к трафику, который покидает ваш модуль. В случае взлома контейнера злоумышленник может начать зондировать окружающую среду по сети. Настройте стратегии для всех пространств имен, которые по умолчанию отклоняют исходящий трафик (https://oreil.ly/RmeUT), а затем добавьте стратегии для ожидаемого вами исходящего трафика.
* Ограничение трафика между модулями. Модули обычно маркируются в соответствии с приложением. Ограничивайте трафик с помощью стратегий, чтобы он был возможен лишь между разрешенными приложениями, а также используйте стратегии для разрешения трафика только из модулей с соответствующими метками.
* Ограничение списка портов. Ограничивайте прием трафика для каждого из приложений только определенными портами.
### Service mesh
Service mesh предоставляет дополнительный набор привилегий и средств контроля за связью приложений друг с другом, реализованный на прикладном уровне (уровнях 5–7 в модели OSI, которую вы видели в начале данной главы).
В экосистеме нативных облачных сервисов существует несколько различных проектов service mesh, включая Istio, Envoy и Linkerd, а также управляемых вариантов от поставщиков облачных сервисов, например AWS App Mesh. Service mesh предоставляет пользователям различные функциональные возможности и преимущества, часть которых связана с безопасностью.
Service mesh можно настроить для использования взаимного TLS в этих вспомогательных контейнерах-прокси, что обеспечивает защищенные, зашифрованные соединения внутри развернутой системы. Благодаря этому злоумышленнику оказывается намного сложнее перехватить трафик, даже если ему и удастся закрепиться в системе.
Service mesh обычно предоставляет возможности для обеспечения соблюдения сетевых стратегий на прикладном уровне, чтобы модули сервиса могли взаимодействовать с другими модулями (внешними или внутренними), только если это разрешено стратегией. А поскольку они работают на прикладном уровне, то существует четкое разделение ответственности между этими стратегиями и сетевыми стратегиями уровней 1–4