Самым важным вопросом при реализации файлового хранилища является отслеживание соответствия файлам блоков на диске.
### Непрерывное размещение
Простейшая схема размещения заключается в хранении каждого файла на диске в виде непрерывной последовательности блоков. Таким образом, на диске с блоками, имеющими размер 1 Кбайт, файл размером 50 Кбайт займет 50 последовательных блоков. При блоках, имеющих размер 2 Кбайт, под него будет выделено 25 последовательных блоков.
Пример хранилища с непрерывным размещением приведен на рис. 4.7 a
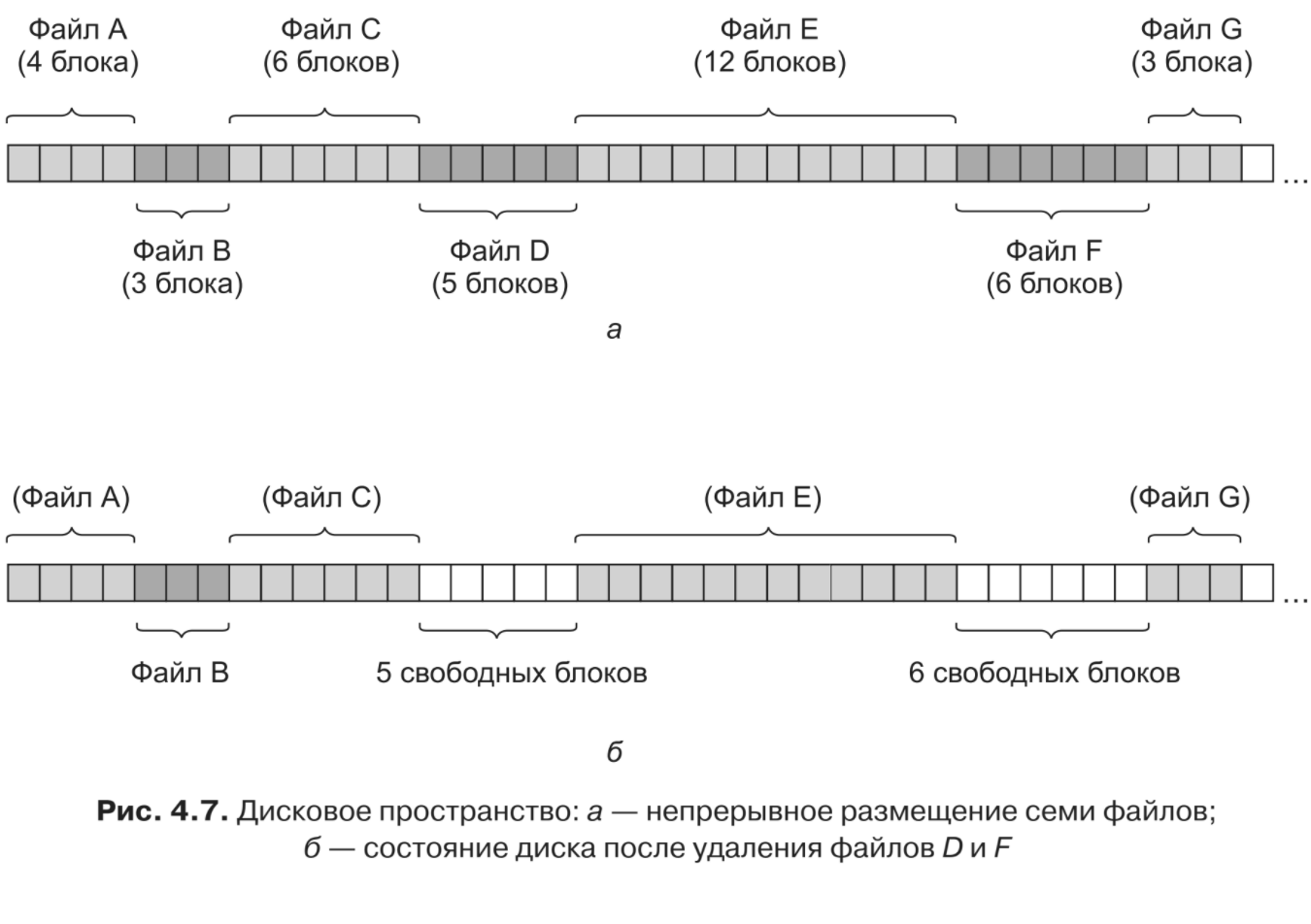
Следует заметить, что каждый файл начинается от границы нового блока, поэтому, если файл A фактически имел длину 3,5 блока, то в конце последнего блока часть пространства будет потеряна впустую.
**Преимущества непрерывного распределения. **
1. Его просто реализовать, поскольку отслеживание местонахождения принадлежащих файлу блоков сводится всего лишь к запоминанию двух чисел: дискового адреса первого блока и количества блоков в файле. При наличии номера первого блока номер любого другого блока может быть вычислен путем простого сложения.
2. Превосходная производительность считывания, поскольку весь файл может быть считан с диска за одну операцию. Для нее потребуется только одна опе- рация позиционирования (на первый блок). После этого никаких позиционирований или ожиданий подхода нужного сектора диска уже не потребуется, поэтому данные поступают на скорости, равной максимальной пропускной способности диска.
** Недостаток **
Со временем диск становится фрагментированным.
Как это происходит, показано на рис. 4.7, б. Были удалены два файла — D и F. Естественно, при удалении файла его блоки освобождаются и на диске остается последовательность свободных блоков. Немедленное уплотнение файлов на диске для устранения такой последовательности свободных блоков («дыры») не осуществляется, поскольку для этого потребуется скопировать все блоки, — а их могут быть миллионы, — следующие за ней, что при использовании больших дисков займет несколько часов или даже дней. В результате, как показано на рис. 4.7, б, диск содержит вперемешку файлы и последовательности свободных блоков.
### Размещение с использованием связанного списка
Заключается в представлении каждого файла в виде связанного списка дисковых блоков
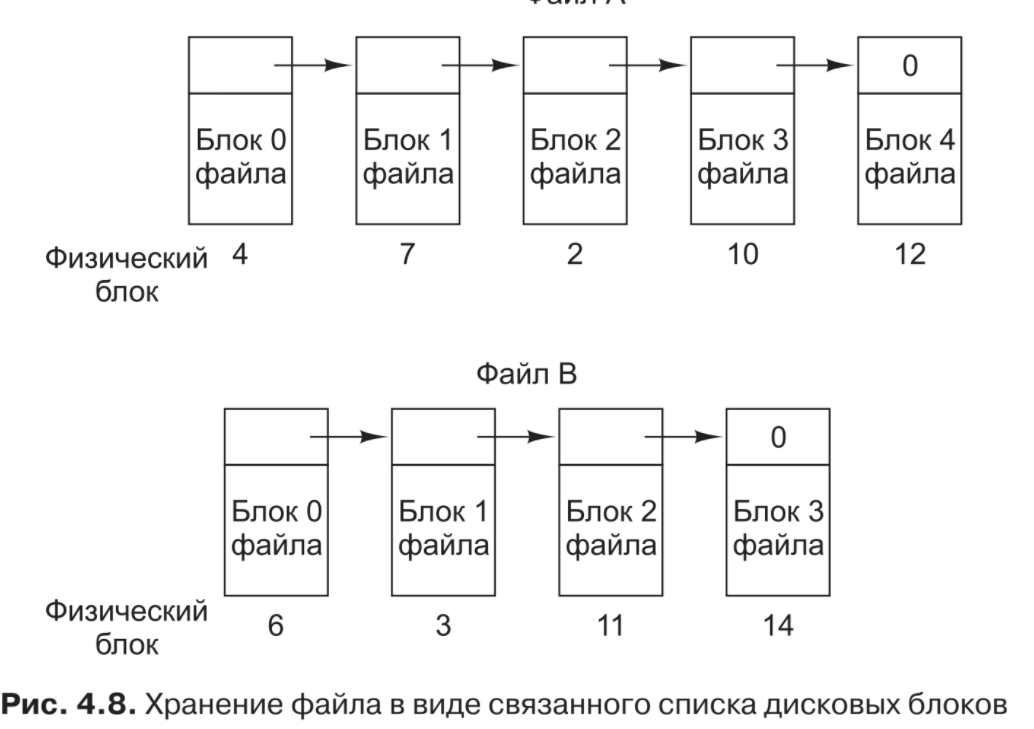
В отличие от непрерывного размещения, в этом методе может быть использован каждый дисковый блок. При этом потери дискового пространства на фрагментацию отсутствуют (за исключением внутренней фрагментации в последнем блоке). Кроме того, достаточно, чтобы в записи каталога хранился только дисковый адрес первого блока. Всю остальную информацию можно найти начиная с этого блока.
В то же время по сравнению с простотой последовательного чтения файла произволь- ный доступ является слишком медленным. Чтобы добраться до блока n, операционной системе нужно начать со стартовой позиции и прочитать поочередно n − 1 предшествующих блоков. Понятно, что осуществление стольких операций чтения окажется мучительно медленным.
К тому же объем хранилища данных в блоках уже не кратен степени числа 2, поскольку несколько байтов отнимает указатель. Хотя это и не смертельно, но необычный размер менее эффективен, поскольку многие программы ведут чтение и запись блоками, раз- мер которых кратен степени числа 2. Когда первые несколько байтов каждого блока заняты указателем на следующий блок, чтение полноценного блока требует получения и соединения информации из двух дисковых блоков, из-за чего возникают дополни- тельные издержки при копировании.
### Размещение с помощью связанного списка, использующего таблицу в памяти
Оба недостатка размещения с помощью связанных списков могут быть устранены за счет изъятия слова указателя из каждого дискового блока и помещения его в таблицу в памяти.

Файл A использует в указанном по- рядке дисковые блоки 4, 7, 2, 10 и 12, а файл B — блоки 6, 3, 11 и 14. Используя таблицу, показанную на рис. 4.9, можно пройти всю цепочку от начального блока 4 до самого конца. То же самое можно проделать начиная с блока 6. Обе цепочки заканчиваются специальным маркером (например, –1), который не является допустимым номером блока. Такая таблица, находящаяся в оперативной памяти, называется FAT (File Allocation Table — таблица размещения файлов).
При использовании такой организации для данных доступен весь блок. Кроме того, намного упрощается произвольный доступ. Хотя для поиска заданного смещения в файле по-прежнему нужно идти по цепочке, эта цепочка целиком находится в памяти, поэто- му проход по ней может осуществляться без обращений к диску. Как и в предыдущем методе, в записи каталога достаточно хранить одно целое число (номер начального блока) и по-прежнему получать возможность определения местоположения всех бло- ков независимо от того, насколько большим будет размер файла.
При использовании такой организации для данных доступен весь блок. Кроме того, на- много упрощается произвольный доступ. Хотя дляОсновным недостатком этого метода является то, что для его работы вся таблица должна постоянно находиться в памяти. Для 1-терабайтного диска, имеющего блоки размером 1 Кбайт, потребовалась бы таблица из 1 млрд записей, по одной для каждого из 1 млрд дисковых блоков. Каждая запись должна состоять как минимум из 3 байт. Для ускорения поиска размер записей должен быть увеличен до 4 байт. Таким об- разом, таблица будет постоянно занимать 3 Гбайт или 2,4 Гбайт оперативной памяти в зависимости от того, как оптимизирована система, под экономию пространства или под экономию времени, что с практической точки зрения выглядит не слишком при- влекательно. Становится очевидным, что идея FAT плохо масштабируется на дискипоиска заданного смещения в файле по-прежнему нужно идти по цепочке, эта цепочка целиком находится в памяти, поэто- му проход по ней может осуществляться без обращений к диску. Как и в предыдущем методе, в записи каталога достаточно хранить одно целое число (номер начального блока) и по-прежнему получать возможность определения местоположения всех бло- ков независимо от того, насколько большим будет размер файла.
Основным недостатком этого метода является то, что для его работы вся таблица должна постоянно находиться в памяти. Для 1-терабайтного диска, имеющего блоки размером 1 Кбайт, потребовалась бы таблица из 1 млрд записей, по одной для каждого из 1 млрд дисковых блоков. Каждая запись должна состоять как минимум из 3 байт. Для ускорения поиска размер записей должен быть увеличен до 4 байт. Таким об- разом, таблица будет постоянно занимать 3 Гбайт или 2,4 Гбайт оперативной памяти в зависимости от того, как оптимизирована система, под экономию пространства или под экономию времени, что с практической точки зрения выглядит не слишком при- влекательно. Становится очевидным, что идея FAT плохо масштабируется на диски больших размеров. Изначально это была файловая система MS-DOS, но она до сих пор полностью поддерживается всеми версиями Windows.