Наиболее распространенным методом сокращения количества обращений к диску является блочное кэширование или буферное кэширование. Для управления кэшем могут применяться различные алгоритмы, но наиболее рас- пространенный из них предусматривает проверку всех запросов для определения того, имеются ли нужные блоки в кэше. Если эти блоки в кэше имеются, то запрос на чтение может быть удовлетворен без обращения к диску. Если блок в кэше отсутствует, то он сначала считывается в кэш, а затем копируется туда, где он нужен. Последующий запрос к тому же самому блоку может быть удовлетворен непосредственно из кэша.
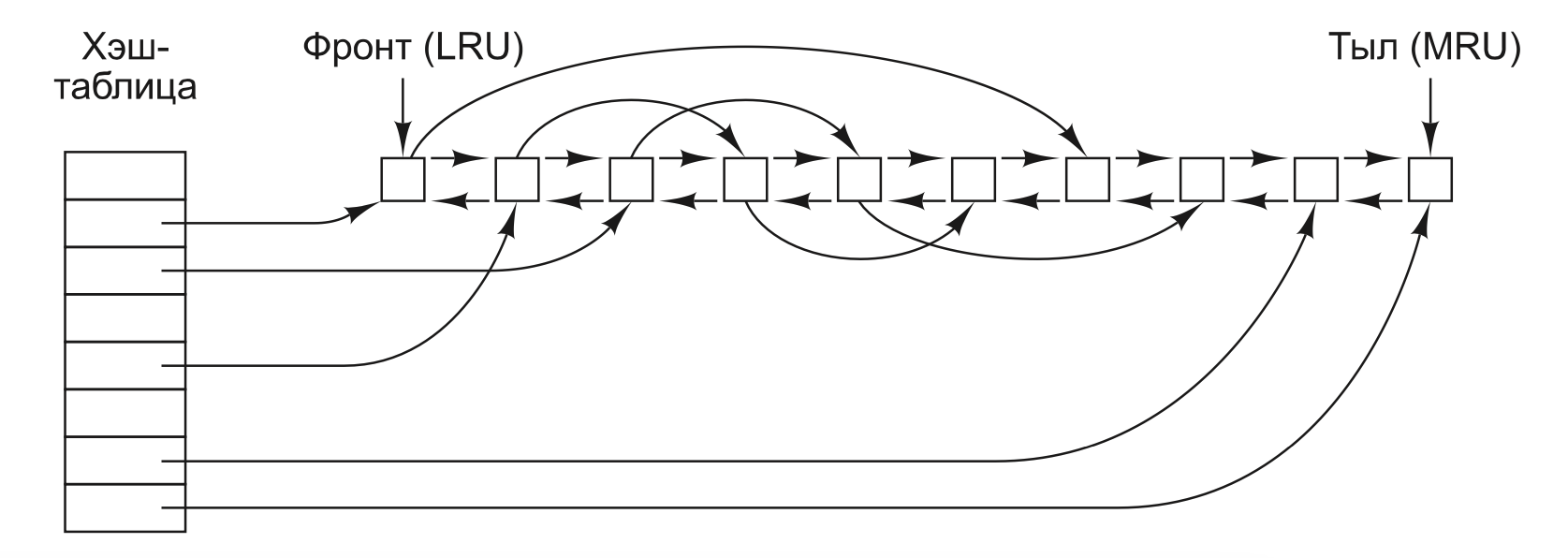
Структура данных буферного кэша
Поскольку в кэше хранится большое количество (обычно несколько тысяч) блоков, нужен какой-нибудь способ быстрого определения, присутствует ли заданный блок в кэше или нет. Обычно хэшируются адрес устройства и диска, а результаты ищутся в хэш-таблице. Все блоки с таким же значением хэша собираются в цепочку (цепочку коллизий) в связанном списке.
Когда блок необходимо загрузить в заполненный кэш, какой-то блок нужно удалить (и переписать на диск, если он был изменен со времени его помещения в кэш). Отличие кэширования от страничной организации состоит в том, что обращения к кэшу происходят относительно нечасто, поэтому вполне допустимо хранить все блоки в строгом порядке LRU (замещения наименее востребованного блока), используя связанные списки.
в дополнение к цепочкам коллизий, начинающихся в хэш- таблице, используется также двунаправленный список, в котором содержатся номера всех блоков в порядке их использования, с наименее востребованным блоком (LRU) в начале этого списка и с наиболее востребованным блоком (MRU) в его конце. Когда происходит обращение к блоку, он может удаляться со своей позиции в двунаправлен- ном списке и помещаться в его конец. Таким образом может поддерживаться точный LRU-порядок.
К сожалению, здесь имеется один подвох. Если какой-нибудь очень важный блок, на- пример блок i-узла, считывается в кэш и изменяется, но не переписывается на диск, то сбой оставляет файловую систему в противоречивом состоянии. Если блок i-узла помещается в конец LRU-цепочки, может пройти довольно много времени, перед тем как он достигнет ее начала и будет записан на диск.
Более того, к некоторым блокам, например блокам i-узлов, редко обращаются дважды за короткий промежуток времени.
Исходя из этих соображений можно прийти к мо- дифицированной LRU-схеме, в которой берутся в расчет два фактора:
1. Велика ли вероятность того, что данный блок вскоре снова понадобится?
2. Важен ли данный блок с точки зрения непротиворечивости файловой системы?
При ответе на оба вопроса блоки могут быть разделены на такие категории, как блоки i-узлов, косвенные блоки, блоки каталогов, заполненные блоки данных и частично заполненные блоки данных. Блоки, которые, возможно, в ближайшее время не пона- добятся, помещаются в начало, а не в конец списка LRU, поэтому вскоре занимаемые ими буферы будут использованы повторно. Блоки, которые вскоре могут снова по- надобиться, например частично заполненные блоки, в которые производится запись, помещаются в конец списка, поэтому они останутся в кэше надолго.
Даже при таких мерах сохранения целостности файловой системы, слишком долгое хранение в кэше блоков данных без их записи на диск также нежелательно.
В UNIX используется системный вызов sync, вынуждающий немедленно записать все измененные блоки на диск. При запуске системы в фоновом режиме начинает действовать программа, которая обычно называется update. Она работает в бесконечном цикле и осуществляет вызовы sync, делая паузу в 30 с между вызовами. В результате при аварии теряется работа не более чем за 30 с.
### Опережающее чтение блока
Второй метод, улучшающий воспринимаемую производительность файловой системы, заключается в попытке получить блоки в кэш еще до того, как они понадобятся, чтобы повысить соотношение удачных обращений к кэшу. В частности, многие файлы чита- ются последовательно. Когда у файловой системы запрашивается блок k какого-нибудь файла, она выполняет запрос, но, завершив его выполнение, проверяет присутствие в кэше блока k + 1. Если этот блок в нем отсутствует, она планирует чтение блока k + 1 в надежде, что, когда он понадобится, он уже будет в кэше. В крайнем случае уже будет в пути. Разумеется, стратегия опережающего чтения работает только для тех файлов, которые считываются последовательно.
### Сокращение количества перемещений блока головок диска
Еще одним важным методом является сокра- щение количества перемещений головок диска за счет размещения блоков с высокой степенью вероятности обращений последовательно, рядом друг с другом, предпочти- тельно на одном и том же цилиндре. При записи выходного файла файловой системе нужно распределить блоки по одному в соответствии с этим требованием. Если запись о свободных блоках ведется в битовом массиве и весь этот массив находится в памя- ти, несложно выбрать свободный блок как можно ближе к предыдущему блоку. Если ведется список свободных блоков, часть из которых находится на диске, то задача размещения блоков как можно ближе друг к другу значительно усложняется.
При распределении блоков система стремится поместить последовательные блоки файла на один и тот же цилиндр.
Еще одно узкое место файловых систем, использующих i-nodes или что-то им подобное, заключается в том, что даже короткие файлы требуют двух обращений к диску: одного для i-node и второго для блока данных.
Все больше компьютеров оснащается твердотельными дисками (solid-state disk, SSD), у которых вообще нет подвижных частей. У этих дисков, созданных по такой же технологии, что и флеш-накопители, произвольный доступ осуществляется почти так же быстро, как и последовательный, и многие проблемы традиционных дисков уходят в прошлое. К сожалению, возникают новые. Например, когда дело доходит до чтения, записи и уда- ления, у SSD-накопителей проявляются особые свойства. В частности, в каждый блок запись может производиться ограниченное количество раз, поэтому большое внимание уделяется равномерному распределению износа по диску.